|
|
@@ -1,1579 +1,305 @@
|
|
|
-# SliceFusion-LLM: 基于调用链的代码分片融合技术研究
|
|
|
-
|
|
|
-## 摘要
|
|
|
-
|
|
|
-本研究提出了一种基于函数调用链的代码分片融合技术(SliceFusion-LLM),旨在将目标代码片段智能地拆分并嵌入到已有程序的多个函数中。该技术融合了程序分析、编译原理和大语言模型(LLM)三大领域的方法论。
|
|
|
-
|
|
|
-具体而言,本研究首先通过词法分析和语法解析构建目标程序的控制流图(Control Flow Graph, CFG),随后基于数据流分析框架计算各基本块的支配关系(Dominance Relation),识别出程序执行的必经点(Critical Point)。在此基础上,利用大语言模型对待融合代码进行语义理解和智能拆分,生成满足依赖约束的代码片段序列。最后,将各片段精确插入到调用链函数的融合点位置,并通过全局变量或参数传递机制实现跨函数的状态共享。
|
|
|
-
|
|
|
-系统还集成了**多层验证机制**,包括基于规则的语法结构验证和基于 LLM 的语义正确性审查,确保融合后代码的正确性。
|
|
|
-
|
|
|
-实验表明,本方法能够有效地将完整代码逻辑分散到多个函数中执行,同时保证程序语义的等价性。该技术可广泛应用于代码混淆、软件水印嵌入、安全漏洞测试、软件保护等领域,具有重要的理论价值和实践意义。
|
|
|
-
|
|
|
-**关键词**:代码融合;控制流图;支配分析;大语言模型;程序变换;代码验证
|
|
|
-
|
|
|
----
|
|
|
-
|
|
|
-## 1. 研究背景与目标
|
|
|
-
|
|
|
-### 1.1 研究动机
|
|
|
-
|
|
|
-在软件安全与逆向工程领域,代码的结构化程度直接影响分析难度。传统的代码混淆技术主要关注单函数内部的变换,如控制流平坦化、不透明谓词插入等。然而,这些技术往往忽略了函数间调用关系所蕴含的混淆潜力。
|
|
|
-
|
|
|
-本研究的核心洞察在于:**利用已有程序的函数调用链作为"载体",将敏感代码分散嵌入,可以显著提高代码的隐蔽性**。这一思路的优势体现在:
|
|
|
-
|
|
|
-1. **利用已有代码结构**:无需构造新的控制流,直接复用现有函数
|
|
|
-2. **语义级分散**:代码片段在语义层面分离,而非仅仅语法层面
|
|
|
-3. **分析抗性**:单独分析任一函数均无法还原完整逻辑
|
|
|
-
|
|
|
-### 1.2 问题形式化定义
|
|
|
-
|
|
|
-设目标程序 $\mathcal{P}$ 包含函数集合 $\mathcal{F}_{all}$,其中存在一条深度为 $n$ 的调用链:
|
|
|
-
|
|
|
-$$
|
|
|
-\mathcal{F} = \{f_1, f_2, \ldots, f_n\} \subseteq \mathcal{F}_{all}
|
|
|
-$$
|
|
|
-
|
|
|
-调用关系满足:
|
|
|
-
|
|
|
-$$
|
|
|
-\forall i \in [1, n-1]: f_i \xrightarrow{\text{call}} f_{i+1}
|
|
|
-$$
|
|
|
-
|
|
|
-给定待融合的目标代码片段 $C_{target}$,本研究的目标是找到一个拆分函数 $\phi$ 和融合函数 $\psi$,使得:
|
|
|
-
|
|
|
-$$
|
|
|
-\phi: C_{target} \rightarrow \{c_1, c_2, \ldots, c_n\}
|
|
|
-$$
|
|
|
-
|
|
|
-$$
|
|
|
-\psi: (\mathcal{F}, \{c_1, \ldots, c_n\}) \rightarrow \mathcal{F}' = \{f_1', f_2', \ldots, f_n'\}
|
|
|
-$$
|
|
|
-
|
|
|
-其中融合后的函数集合 $\mathcal{F}'$ 需满足以下**语义等价性约束**:
|
|
|
-
|
|
|
-$$
|
|
|
-\boxed{\text{Exec}(f_1') \equiv \text{Exec}(f_1) \circ \text{Exec}(C_{target})}
|
|
|
-$$
|
|
|
-
|
|
|
-即执行 $f_1'$ 的效果等价于先执行原始 $f_1$ 再执行目标代码 $C_{target}$。
|
|
|
-
|
|
|
-更精确地,设 $\sigma$ 为程序状态,$\llbracket \cdot \rrbracket$ 为语义函数,则:
|
|
|
-
|
|
|
-$$
|
|
|
-\llbracket f_1' \rrbracket(\sigma_0) = \llbracket C_{target} \rrbracket(\llbracket f_1 \rrbracket(\sigma_0))
|
|
|
-$$
|
|
|
-
|
|
|
-### 1.3 约束条件
|
|
|
-
|
|
|
-代码拆分需满足以下约束:
|
|
|
-
|
|
|
-**约束 1(完整性约束)**:所有片段的并集覆盖原始代码的全部语句:
|
|
|
-
|
|
|
-$$
|
|
|
-\bigcup_{i=1}^{n} \text{Stmts}(c_i) \supseteq \text{Stmts}(C_{target})
|
|
|
-$$
|
|
|
-
|
|
|
-**约束 2(依赖约束)**:若语句 $s_j$ 数据依赖于语句 $s_i$(记作 $s_i \xrightarrow{dep} s_j$),且 $s_i \in c_k$,$s_j \in c_l$,则:
|
|
|
-
|
|
|
-$$
|
|
|
-s_i \xrightarrow{dep} s_j \Rightarrow k \leq l
|
|
|
-$$
|
|
|
-
|
|
|
-**约束 3(可达性约束)**:对于任意片段 $c_i$,其插入位置 $p_i \in f_i$ 必须在调用 $f_{i+1}$ 之前执行:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Dominates}(p_i, \text{CallSite}(f_{i+1}))
|
|
|
-$$
|
|
|
-
|
|
|
-### 1.4 研究目标
|
|
|
-
|
|
|
-本研究的具体目标包括:
|
|
|
-
|
|
|
-1. **设计高效的 CFG 构建算法**:支持 C/C++ 代码的控制流分析
|
|
|
-2. **实现精确的支配节点计算**:基于迭代数据流分析框架
|
|
|
-3. **开发智能代码拆分方法**:利用 LLM 进行语义感知的代码分片
|
|
|
-4. **构建完整的融合系统**:支持多种状态传递策略
|
|
|
-5. **验证方法的有效性**:通过实验评估融合效果
|
|
|
-
|
|
|
----
|
|
|
-
|
|
|
-## 2. 理论基础
|
|
|
-
|
|
|
-### 2.1 控制流图(Control Flow Graph, CFG)
|
|
|
-
|
|
|
-#### 2.1.1 定义与性质
|
|
|
-
|
|
|
-**定义 2.1(控制流图)**:程序 $P$ 的控制流图是一个四元组:
|
|
|
-
|
|
|
-$$
|
|
|
-G_{CFG} = (V, E, v_{entry}, V_{exit})
|
|
|
-$$
|
|
|
-
|
|
|
-其中:
|
|
|
-- $V = \{v_1, v_2, \ldots, v_m\}$ 为**基本块**(Basic Block)的有限集合
|
|
|
-- $E \subseteq V \times V$ 为**控制流边**的集合
|
|
|
-- $v_{entry} \in V$ 为唯一的**入口基本块**
|
|
|
-- $V_{exit} \subseteq V$ 为**出口基本块**的集合
|
|
|
-
|
|
|
-**定义 2.2(基本块)**:基本块是满足以下条件的最大指令序列 $B = \langle i_1, i_2, \ldots, i_k \rangle$:
|
|
|
-
|
|
|
-1. **单入口**:只有 $i_1$ 可以从外部跳转进入
|
|
|
-2. **单出口**:只有 $i_k$ 可以跳转到外部
|
|
|
-3. **顺序执行**:若 $i_j$ 执行,则 $i_{j+1}, \ldots, i_k$ 必然顺序执行
|
|
|
-
|
|
|
-形式化表示:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{BasicBlock}(B) \Leftrightarrow \begin{cases}
|
|
|
-\text{Entry}(B) = \{i_1\} \\
|
|
|
-\text{Exit}(B) = \{i_k\} \\
|
|
|
-\forall j \in [1, k-1]: \text{Succ}(i_j) = \{i_{j+1}\}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-#### 2.1.2 基本块识别算法
|
|
|
-
|
|
|
-基本块的首指令(Leader)识别规则:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Leader}(i) = \begin{cases}
|
|
|
-\text{True} & \text{if } i \text{ 是程序的第一条指令} \\
|
|
|
-\text{True} & \text{if } i \text{ 是某条跳转指令的目标} \\
|
|
|
-\text{True} & \text{if } i \text{ 紧跟在某条跳转指令之后} \\
|
|
|
-\text{False} & \text{otherwise}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-**算法 2.1:基本块划分算法**
|
|
|
-
|
|
|
-```
|
|
|
-输入: 指令序列 I = [i_1, i_2, ..., i_n]
|
|
|
-输出: 基本块集合 B
|
|
|
-
|
|
|
-1: Leaders ← {i_1} // 第一条指令是 leader
|
|
|
-2: for each instruction i_j in I do
|
|
|
-3: if i_j is a branch instruction then
|
|
|
-4: Leaders ← Leaders ∪ {target(i_j)}
|
|
|
-5: if j < n then
|
|
|
-6: Leaders ← Leaders ∪ {i_{j+1}}
|
|
|
-7: B ← ∅
|
|
|
-8: for each leader l in sorted(Leaders) do
|
|
|
-9: b ← new BasicBlock starting at l
|
|
|
-10: extend b until next leader or end
|
|
|
-11: B ← B ∪ {b}
|
|
|
-12: return B
|
|
|
-```
|
|
|
-
|
|
|
-#### 2.1.3 边的构建
|
|
|
-
|
|
|
-控制流边 $(v_i, v_j) \in E$ 当且仅当:
|
|
|
-
|
|
|
-$$
|
|
|
-(v_i, v_j) \in E \Leftrightarrow \begin{cases}
|
|
|
-\text{last}(v_i) \text{ 是无条件跳转到 } \text{first}(v_j) \\
|
|
|
-\lor\ \text{last}(v_i) \text{ 是条件跳转,} v_j \text{ 是可能目标} \\
|
|
|
-\lor\ \text{last}(v_i) \text{ 不是跳转,} v_j \text{ 是顺序后继}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-#### 2.1.4 CFG 的性质
|
|
|
-
|
|
|
-**性质 2.1(连通性)**:从 $v_{entry}$ 可达所有 $v \in V$:
|
|
|
-
|
|
|
-$$
|
|
|
-\forall v \in V: v_{entry} \leadsto v
|
|
|
-$$
|
|
|
-
|
|
|
-**性质 2.2(规范性)**:任意 $v_{exit} \in V_{exit}$ 的后继集合为空:
|
|
|
-
|
|
|
-$$
|
|
|
-\forall v \in V_{exit}: \text{Succ}(v) = \emptyset
|
|
|
-$$
|
|
|
-
|
|
|
-### 2.2 支配关系(Dominance Relation)
|
|
|
-
|
|
|
-#### 2.2.1 基本定义
|
|
|
-
|
|
|
-**定义 2.3(支配)**:在 CFG $G = (V, E, v_{entry}, V_{exit})$ 中,节点 $d$ **支配** 节点 $n$(记作 $d\ \text{dom}\ n$),当且仅当从 $v_{entry}$ 到 $n$ 的每条路径都经过 $d$:
|
|
|
-
|
|
|
-$$
|
|
|
-d\ \text{dom}\ n \Leftrightarrow \forall \text{ path } \pi: v_{entry} \leadsto n,\ d \in \pi
|
|
|
-$$
|
|
|
-
|
|
|
-等价的集合论定义:
|
|
|
-
|
|
|
-$$
|
|
|
-d\ \text{dom}\ n \Leftrightarrow d \in \text{Dom}(n)
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $\text{Dom}(n)$ 是节点 $n$ 的支配者集合。
|
|
|
-
|
|
|
-**定义 2.4(严格支配)**:$d$ **严格支配** $n$(记作 $d\ \text{sdom}\ n$):
|
|
|
-
|
|
|
-$$
|
|
|
-d\ \text{sdom}\ n \Leftrightarrow d\ \text{dom}\ n \land d \neq n
|
|
|
-$$
|
|
|
-
|
|
|
-**定义 2.5(直接支配者)**:节点 $n \neq v_{entry}$ 的**直接支配者**(immediate dominator)$\text{idom}(n)$ 是 $n$ 的严格支配者中最接近 $n$ 的节点:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{idom}(n) = d \Leftrightarrow d\ \text{sdom}\ n \land \forall d': d'\ \text{sdom}\ n \Rightarrow d'\ \text{dom}\ d
|
|
|
-$$
|
|
|
-
|
|
|
-**定理 2.1**:除入口节点外,每个节点有且仅有一个直接支配者。
|
|
|
-
|
|
|
-#### 2.2.2 支配集合的计算
|
|
|
-
|
|
|
-支配关系可通过数据流分析的迭代算法计算。数据流方程为:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Dom}(n) = \begin{cases}
|
|
|
-\{v_{entry}\} & \text{if } n = v_{entry} \\
|
|
|
-\{n\} \cup \left( \displaystyle\bigcap_{p \in \text{Pred}(n)} \text{Dom}(p) \right) & \text{otherwise}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-**算法 2.2:支配集合迭代计算**
|
|
|
-
|
|
|
-```
|
|
|
-输入: CFG G = (V, E, v_entry, V_exit)
|
|
|
-输出: 每个节点的支配集合 Dom
|
|
|
-
|
|
|
-1: Dom(v_entry) ← {v_entry}
|
|
|
-2: for each v ∈ V \ {v_entry} do
|
|
|
-3: Dom(v) ← V // 初始化为全集
|
|
|
-4: repeat
|
|
|
-5: changed ← false
|
|
|
-6: for each v ∈ V \ {v_entry} do
|
|
|
-7: new_dom ← {v} ∪ (⋂_{p ∈ Pred(v)} Dom(p))
|
|
|
-8: if new_dom ≠ Dom(v) then
|
|
|
-9: Dom(v) ← new_dom
|
|
|
-10: changed ← true
|
|
|
-11: until not changed
|
|
|
-12: return Dom
|
|
|
-```
|
|
|
-
|
|
|
-**复杂度分析**:设 $|V| = n$,$|E| = m$,则:
|
|
|
-- 空间复杂度:$O(n^2)$(存储所有支配集合)
|
|
|
-- 时间复杂度:$O(n \cdot m)$(最坏情况下的迭代次数)
|
|
|
-
|
|
|
-#### 2.2.3 支配树(Dominator Tree)
|
|
|
-
|
|
|
-**定义 2.6(支配树)**:CFG 的支配树 $T_{dom} = (V, E_{dom})$ 是一棵以 $v_{entry}$ 为根的树,其中:
|
|
|
-
|
|
|
-$$
|
|
|
-(d, n) \in E_{dom} \Leftrightarrow d = \text{idom}(n)
|
|
|
-$$
|
|
|
-
|
|
|
-支配树的性质:
|
|
|
-
|
|
|
-$$
|
|
|
-d\ \text{dom}\ n \Leftrightarrow d \text{ 是 } T_{dom} \text{ 中 } n \text{ 的祖先}
|
|
|
-$$
|
|
|
-
|
|
|
-### 2.3 必经点(Critical Point)
|
|
|
-
|
|
|
-#### 2.3.1 定义
|
|
|
-
|
|
|
-**定义 2.7(必经点)**:在 CFG $G$ 中,节点 $v$ 是**必经点**,当且仅当移除 $v$ 后,从 $v_{entry}$ 无法到达任何出口节点:
|
|
|
-
|
|
|
-$$
|
|
|
-v \in \mathcal{C}(G) \Leftrightarrow \forall v_{exit} \in V_{exit}: v_{entry} \not\leadsto_{G \setminus \{v\}} v_{exit}
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $G \setminus \{v\}$ 表示从 $G$ 中移除节点 $v$ 及其关联边后得到的子图。
|
|
|
-
|
|
|
-等价定义:
|
|
|
-
|
|
|
-$$
|
|
|
-v \in \mathcal{C}(G) \Leftrightarrow v\ \text{dom}\ v_{exit},\ \forall v_{exit} \in V_{exit}
|
|
|
-$$
|
|
|
-
|
|
|
-#### 2.3.2 必经点的判定
|
|
|
-
|
|
|
-**算法 2.3:必经点判定**
|
|
|
-
|
|
|
-```
|
|
|
-输入: CFG G, 待检查节点 v
|
|
|
-输出: v 是否为必经点
|
|
|
-
|
|
|
-1: if v = v_entry then
|
|
|
-2: return True
|
|
|
-3: G' ← G \ {v} // 移除节点 v
|
|
|
-4: for each v_exit ∈ V_exit do
|
|
|
-5: if Reachable(G', v_entry, v_exit) then
|
|
|
-6: return False
|
|
|
-7: return True
|
|
|
-```
|
|
|
-
|
|
|
-**定理 2.2**:必经点集合 $\mathcal{C}(G)$ 等于所有出口节点支配集合的交集:
|
|
|
-
|
|
|
-$$
|
|
|
-\mathcal{C}(G) = \bigcap_{v_{exit} \in V_{exit}} \text{Dom}(v_{exit})
|
|
|
-$$
|
|
|
-
|
|
|
-#### 2.3.3 必经点的性质
|
|
|
-
|
|
|
-**性质 2.3(链式结构)**:必经点集合在支配树上形成一条从根到某节点的链:
|
|
|
-
|
|
|
-$$
|
|
|
-\forall c_1, c_2 \in \mathcal{C}(G): c_1\ \text{dom}\ c_2 \lor c_2\ \text{dom}\ c_1
|
|
|
-$$
|
|
|
-
|
|
|
-**性质 2.4(必经性传递)**:若 $c_1\ \text{dom}\ c_2$ 且 $c_2 \in \mathcal{C}(G)$,则 $c_1 \in \mathcal{C}(G)$。
|
|
|
-
|
|
|
-### 2.4 融合点(Fusion Point)
|
|
|
-
|
|
|
-#### 2.4.1 定义与条件
|
|
|
-
|
|
|
-**定义 2.8(融合点)**:适合代码插入的位置,需满足以下条件:
|
|
|
-
|
|
|
-$$
|
|
|
-v \in \mathcal{P}_{fusion}(G) \Leftrightarrow v \in \mathcal{C}(G) \land \Phi_{struct}(v) \land \Phi_{flow}(v)
|
|
|
-$$
|
|
|
-
|
|
|
-其中:
|
|
|
-
|
|
|
-**结构条件** $\Phi_{struct}(v)$:
|
|
|
-
|
|
|
-$$
|
|
|
-\Phi_{struct}(v) \Leftrightarrow |\text{Pred}(v)| \leq 1 \land |\text{Succ}(v)| \leq 1
|
|
|
-$$
|
|
|
-
|
|
|
-**控制流条件** $\Phi_{flow}(v)$:前驱和后继的跳转必须是无条件跳转:
|
|
|
-
|
|
|
-$$
|
|
|
-\Phi_{flow}(v) \Leftrightarrow \neg\text{IsConditionalBranch}(\text{Pred}(v) \to v) \land \neg\text{IsConditionalBranch}(v \to \text{Succ}(v))
|
|
|
-$$
|
|
|
-
|
|
|
-#### 2.4.2 融合点的优先级
|
|
|
-
|
|
|
-当存在多个融合点时,按以下优先级选择:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Priority}(v) = \alpha \cdot \text{Depth}(v) + \beta \cdot \text{Centrality}(v) + \gamma \cdot \text{Stability}(v)
|
|
|
-$$
|
|
|
-
|
|
|
-其中:
|
|
|
-- $\text{Depth}(v)$:在支配树中的深度
|
|
|
-- $\text{Centrality}(v)$:在 CFG 中的中心性度量
|
|
|
-- $\text{Stability}(v)$:基本块的大小(越大越稳定)
|
|
|
-- $\alpha, \beta, \gamma$:权重系数
|
|
|
+<p align="center">
|
|
|
+ <img src="assets/over_all.jpg" alt="SliceFusion Overview" width="600"/>
|
|
|
+</p>
|
|
|
+
|
|
|
+<h1 align="center">SliceFusion-LLM</h1>
|
|
|
+
|
|
|
+<p align="center">
|
|
|
+ <strong>基于函数调用链的智能代码分片融合技术</strong>
|
|
|
+</p>
|
|
|
+
|
|
|
+<p align="center">
|
|
|
+ <a href="#特性">特性</a> •
|
|
|
+ <a href="#快速开始">快速开始</a> •
|
|
|
+ <a href="#使用示例">使用示例</a> •
|
|
|
+ <a href="#技术架构">架构</a> •
|
|
|
+ <a href="#文档">文档</a>
|
|
|
+</p>
|
|
|
+
|
|
|
+<p align="center">
|
|
|
+ <img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="Python 3.10+"/>
|
|
|
+ <img src="https://img.shields.io/badge/language-C%2FC++-orange.svg" alt="C/C++"/>
|
|
|
+ <img src="https://img.shields.io/badge/LLM-Qwen-green.svg" alt="LLM Powered"/>
|
|
|
+ <img src="https://img.shields.io/badge/license-MIT-lightgrey.svg" alt="MIT License"/>
|
|
|
+</p>
|
|
|
|
|
|
---
|
|
|
|
|
|
-## 3. 方法设计
|
|
|
-
|
|
|
-### 3.1 系统架构
|
|
|
-
|
|
|
-SliceFusion-LLM 系统采用模块化设计,由六个核心层次构成:
|
|
|
-
|
|
|
-```
|
|
|
-┌─────────────────────────────────────────────────────────────────────────────┐
|
|
|
-│ SliceFusion-LLM System │
|
|
|
-├─────────────────────────────────────────────────────────────────────────────┤
|
|
|
-│ │
|
|
|
-│ ┌─────────────────┐ │
|
|
|
-│ │ Input Layer │ │
|
|
|
-│ │ ┌───────────┐ │ │
|
|
|
-│ │ │ 源代码数据 │ │ │
|
|
|
-│ │ │ (JSONL) │ │ │
|
|
|
-│ │ └─────┬─────┘ │ │
|
|
|
-│ └────────┼────────┘ │
|
|
|
-│ │ │
|
|
|
-│ ▼ │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────────────┐ │
|
|
|
-│ │ Data Processing Layer │ │
|
|
|
-│ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │
|
|
|
-│ │ │ 调用关系提取 │───▶│ 调用链分组 │───▶│ 深度筛选 │ │ │
|
|
|
-│ │ │ extract_call_ │ │ 按连通分量分组 │ │ filter_by_ │ │ │
|
|
|
-│ │ │ relations.py │ │ │ │ call_depth.py │ │ │
|
|
|
-│ │ └─────────────────┘ └─────────────────┘ └───────┬─────────┘ │ │
|
|
|
-│ └────────────────────────────────────────────────────────┼────────────┘ │
|
|
|
-│ │ │
|
|
|
-│ ▼ │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────────────┐ │
|
|
|
-│ │ Analysis Layer │ │
|
|
|
-│ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │
|
|
|
-│ │ │ CFG 构建 │───▶│ 支配分析 │───▶│ 融合点识别 │ │ │
|
|
|
-│ │ │ cfg_analyzer.py │ │ dominator_ │ │ │ │ │
|
|
|
-│ │ │ │ │ analyzer.py │ │ │ │ │
|
|
|
-│ │ └─────────────────┘ └─────────────────┘ └───────┬─────────┘ │ │
|
|
|
-│ └────────────────────────────────────────────────────────┼────────────┘ │
|
|
|
-│ │ │
|
|
|
-│ ▼ │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────────────┐ │
|
|
|
-│ │ Splitting Layer │ │
|
|
|
-│ │ ┌─────────────────────────────────────────────────────────────┐ │ │
|
|
|
-│ │ │ LLM Code Splitter │ │ │
|
|
|
-│ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │
|
|
|
-│ │ │ │ Prompt 构建 │───▶│ LLM 调用 │───▶│ 结果解析 │ │ │ │
|
|
|
-│ │ │ │ │ │ (Qwen API) │ │ │ │ │ │
|
|
|
-│ │ │ └─────────────┘ └─────────────┘ └──────┬──────┘ │ │ │
|
|
|
-│ │ └──────────────────────────────────────────────┼──────────────┘ │ │
|
|
|
-│ └─────────────────────────────────────────────────┼───────────────────┘ │
|
|
|
-│ │ │
|
|
|
-│ ▼ │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────────────┐ │
|
|
|
-│ │ Fusion Layer │ │
|
|
|
-│ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │
|
|
|
-│ │ │ 状态生成 │───▶│ 代码插入 │───▶│ 代码生成 │ │ │
|
|
|
-│ │ │ (Global/Param) │ │ code_fusion.py │ │ main.py │ │ │
|
|
|
-│ │ └─────────────────┘ └─────────────────┘ └───────┬─────────┘ │ │
|
|
|
-│ └────────────────────────────────────────────────────────┼────────────┘ │
|
|
|
-│ │ │
|
|
|
-│ ▼ │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────────────┐ │
|
|
|
-│ │ Verification Layer │ │
|
|
|
-│ │ ┌─────────────────────────────────────────────────────────────┐ │ │
|
|
|
-│ │ │ Verification Agent │ │ │
|
|
|
-│ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │
|
|
|
-│ │ │ │ 语法验证器 │───▶│ 语义审查器 │───▶│ 综合报告 │ │ │ │
|
|
|
-│ │ │ │ (规则检查) │ │ (LLM 审查) │ │ 生成 │ │ │ │
|
|
|
-│ │ │ └─────────────┘ └─────────────┘ └──────┬──────┘ │ │ │
|
|
|
-│ │ └──────────────────────────────────────────────┼──────────────┘ │ │
|
|
|
-│ └─────────────────────────────────────────────────┼───────────────────┘ │
|
|
|
-│ │ │
|
|
|
-│ ▼ │
|
|
|
-│ ┌─────────────────┐ │
|
|
|
-│ │ Output Layer │ │
|
|
|
-│ │ ┌───────────┐ │ │
|
|
|
-│ │ │ 融合代码 │ │ │
|
|
|
-│ │ │ (.c 文件) │ │ │
|
|
|
-│ │ └───────────┘ │ │
|
|
|
-│ └─────────────────┘ │
|
|
|
-│ │
|
|
|
-└─────────────────────────────────────────────────────────────────────────────┘
|
|
|
-```
|
|
|
-
|
|
|
-### 3.2 调用链分析
|
|
|
-
|
|
|
-#### 3.2.1 函数调用关系提取
|
|
|
-
|
|
|
-从代码中提取函数调用关系,构建调用图 $G_{call} = (V_{func}, E_{call})$:
|
|
|
-
|
|
|
-$$
|
|
|
-(f_i, f_j) \in E_{call} \Leftrightarrow f_i \text{ 的函数体中存在对 } f_j \text{ 的调用}
|
|
|
-$$
|
|
|
-
|
|
|
-调用关系提取采用正则表达式匹配:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Callees}(f) = \{g \mid \exists \text{ pattern } ``g\text{(}'' \in \text{Body}(f)\}
|
|
|
-$$
|
|
|
-
|
|
|
-#### 3.2.2 调用链深度计算
|
|
|
-
|
|
|
-定义调用链深度函数 $d: V_{func} \times V_{func} \to \mathbb{N}$:
|
|
|
-
|
|
|
-$$
|
|
|
-d(f_i, f_j) = \begin{cases}
|
|
|
-0 & \text{if } f_i = f_j \\
|
|
|
-1 + \min_{f_k \in \text{Callees}(f_i)} d(f_k, f_j) & \text{if } f_i \neq f_j \land f_i \leadsto f_j \\
|
|
|
-\infty & \text{otherwise}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-最长调用链深度:
|
|
|
-
|
|
|
-$$
|
|
|
-D_{max}(G_{call}) = \max_{f_i, f_j \in V_{func}} d(f_i, f_j)
|
|
|
-$$
|
|
|
-
|
|
|
-#### 3.2.3 调用链分组
|
|
|
-
|
|
|
-使用 Union-Find 算法将有调用关系的函数分组。设 $\sim$ 为传递闭包关系:
|
|
|
-
|
|
|
-$$
|
|
|
-f_i \sim f_j \Leftrightarrow f_i \leadsto f_j \lor f_j \leadsto f_i
|
|
|
-$$
|
|
|
-
|
|
|
-则分组 $\mathcal{G}$ 为等价类:
|
|
|
-
|
|
|
-$$
|
|
|
-\mathcal{G} = V_{func} / \sim = \{[f]_\sim \mid f \in V_{func}\}
|
|
|
-$$
|
|
|
-
|
|
|
-### 3.3 代码拆分算法
|
|
|
-
|
|
|
-#### 3.3.1 问题建模
|
|
|
-
|
|
|
-代码拆分可建模为约束满足问题(CSP):
|
|
|
-
|
|
|
-$$
|
|
|
-\text{CSP}_{split} = (X, D, C)
|
|
|
-$$
|
|
|
-
|
|
|
-其中:
|
|
|
-- **变量** $X = \{x_1, x_2, \ldots, x_n\}$:每个变量表示一个代码片段
|
|
|
-- **域** $D$:每个变量的取值范围为原始代码的语句子集
|
|
|
-- **约束** $C$:包括完整性、依赖性、平衡性约束
|
|
|
-
|
|
|
-**约束 C1(完整性)**:
|
|
|
-
|
|
|
-$$
|
|
|
-\bigcup_{i=1}^{n} x_i = \text{Stmts}(C_{target})
|
|
|
-$$
|
|
|
-
|
|
|
-**约束 C2(不重叠)**:
|
|
|
-
|
|
|
-$$
|
|
|
-\forall i \neq j: x_i \cap x_j = \emptyset
|
|
|
-$$
|
|
|
-
|
|
|
-**约束 C3(依赖保持)**:
|
|
|
-
|
|
|
-$$
|
|
|
-\forall s_a \xrightarrow{dep} s_b: (\text{Index}(s_a) \leq \text{Index}(s_b))
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $\text{Index}(s)$ 返回语句 $s$ 所属片段的索引。
|
|
|
-
|
|
|
-#### 3.3.2 LLM 辅助拆分
|
|
|
-
|
|
|
-利用大语言模型进行语义感知的代码拆分。设 LLM 为函数 $\mathcal{L}$:
|
|
|
-
|
|
|
-$$
|
|
|
-\mathcal{L}: (\text{Prompt}, \text{Context}) \rightarrow \text{Response}
|
|
|
-$$
|
|
|
-
|
|
|
-Prompt 模板构建:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Prompt} = \text{Template}(C_{target}, n, \mathcal{F}, M, \text{Examples})
|
|
|
-$$
|
|
|
-
|
|
|
-其中:
|
|
|
-- $C_{target}$:目标代码
|
|
|
-- $n$:拆分片段数
|
|
|
-- $\mathcal{F}$:调用链函数名列表
|
|
|
-- $M \in \{\text{global}, \text{parameter}\}$:状态传递方法
|
|
|
-- $\text{Examples}$:Few-shot 示例
|
|
|
-
|
|
|
-LLM 输出解析:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Parse}: \text{JSON} \rightarrow (\{c_i\}_{i=1}^n, \mathcal{S}, \text{Decl})
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $\mathcal{S}$ 为共享状态集合,$\text{Decl}$ 为声明代码。
|
|
|
+## 概述
|
|
|
|
|
|
-#### 3.3.3 Fallback 机制
|
|
|
+**SliceFusion-LLM** 是一个智能代码融合工具,能够将目标代码片段智能地拆分并嵌入到已有程序的多个函数调用链中。该技术融合了程序分析、编译原理和大语言模型(LLM)三大领域的方法论。
|
|
|
|
|
|
-当 LLM 调用失败时,采用启发式拆分:
|
|
|
-
|
|
|
-**算法 3.1:启发式代码拆分**
|
|
|
+### 核心思路
|
|
|
|
|
|
```
|
|
|
-输入: 代码 C, 片段数 n
|
|
|
-输出: 代码片段列表 {c_1, ..., c_n}
|
|
|
-
|
|
|
-1: stmts ← ParseStatements(C)
|
|
|
-2: k ← |stmts|
|
|
|
-3: if k < n then
|
|
|
-4: // 补充空片段
|
|
|
-5: for i = 1 to k do
|
|
|
-6: c_i ← stmts[i]
|
|
|
-7: for i = k+1 to n do
|
|
|
-8: c_i ← "// empty"
|
|
|
-9: else
|
|
|
-10: // 均分
|
|
|
-11: chunk_size ← ⌊k / n⌋
|
|
|
-12: for i = 1 to n do
|
|
|
-13: start ← (i-1) × chunk_size + 1
|
|
|
-14: end ← min(i × chunk_size, k) if i < n else k
|
|
|
-15: c_i ← Join(stmts[start:end])
|
|
|
-16: return {c_1, ..., c_n}
|
|
|
+目标代码 → [LLM智能拆分] → 代码片段序列 → [融合到调用链] → 混淆后代码
|
|
|
+ │ │
|
|
|
+ └──────── 语义等价性验证 ◄─────────────────────┘
|
|
|
```
|
|
|
|
|
|
-### 3.4 状态传递方法
|
|
|
-
|
|
|
-#### 3.4.1 全局变量法
|
|
|
-
|
|
|
-**定义 3.1(全局状态空间)**:设共享变量集合为 $\mathcal{S} = \{s_1, s_2, \ldots, s_k\}$,全局状态空间为:
|
|
|
-
|
|
|
-$$
|
|
|
-\mathcal{G} = \{g_i = \text{global}(s_i) \mid s_i \in \mathcal{S}\}
|
|
|
-$$
|
|
|
-
|
|
|
-变量重命名映射 $\rho_{global}: \mathcal{S} \to \mathcal{G}$:
|
|
|
-
|
|
|
-$$
|
|
|
-\rho_{global}(s_i) = g\_s_i \quad (\text{添加前缀 } g\_)
|
|
|
-$$
|
|
|
-
|
|
|
-**全局声明生成**:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Decl}_{global} = \bigcup_{s_i \in \mathcal{S}} \text{``static } T_i\ g\_s_i\text{;''}
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $T_i$ 为 $s_i$ 的类型。
|
|
|
-
|
|
|
-**代码变换**:
|
|
|
-
|
|
|
-$$
|
|
|
-c_i' = c_i[s_j \mapsto g\_s_j,\ \forall s_j \in \mathcal{S}]
|
|
|
-$$
|
|
|
-
|
|
|
-**形式化语义**:
|
|
|
-
|
|
|
-设 $\sigma_G$ 为全局状态,$\sigma_L$ 为局部状态,则:
|
|
|
-
|
|
|
-$$
|
|
|
-\llbracket c_i' \rrbracket(\sigma_G, \sigma_L) = \llbracket c_i \rrbracket(\sigma_G \cup \sigma_L)
|
|
|
-$$
|
|
|
-
|
|
|
-#### 3.4.2 参数传递法
|
|
|
-
|
|
|
-**定义 3.2(状态结构体)**:定义结构体类型 $\Sigma$:
|
|
|
-
|
|
|
-$$
|
|
|
-\Sigma = \text{struct FusionState} \{T_1\ s_1;\ T_2\ s_2;\ \ldots;\ T_k\ s_k;\}
|
|
|
-$$
|
|
|
-
|
|
|
-**函数签名变换**:
|
|
|
-
|
|
|
-$$
|
|
|
-f_i: (A_1, \ldots, A_m) \to R \quad \Longrightarrow \quad f_i': (A_1, \ldots, A_m, \Sigma^*\ state) \to R
|
|
|
-$$
|
|
|
-
|
|
|
-**变量访问变换**:
|
|
|
-
|
|
|
-$$
|
|
|
-\rho_{param}(s_j) = state \to s_j
|
|
|
-$$
|
|
|
-
|
|
|
-**代码变换**:
|
|
|
-
|
|
|
-$$
|
|
|
-c_i' = c_i[s_j \mapsto state \to s_j,\ \forall s_j \in \mathcal{S}]
|
|
|
-$$
|
|
|
-
|
|
|
-**函数调用变换**:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Call}(f_{i+1}, args) \Longrightarrow \text{Call}(f_{i+1}', args, state)
|
|
|
-$$
|
|
|
-
|
|
|
-**初始化代码**:
|
|
|
-
|
|
|
-```c
|
|
|
-FusionState state_data;
|
|
|
-memset(&state_data, 0, sizeof(state_data));
|
|
|
-FusionState* state = &state_data;
|
|
|
-```
|
|
|
-
|
|
|
-#### 3.4.3 两种方法的对比
|
|
|
-
|
|
|
-| 特性 | 全局变量法 | 参数传递法 |
|
|
|
-|------|-----------|-----------|
|
|
|
-| 实现复杂度 | $O(k)$ | $O(k + n)$ |
|
|
|
-| 函数签名修改 | 否 | 是 |
|
|
|
-| 线程安全 | ❌ | ✅ |
|
|
|
-| 可重入性 | ❌ | ✅ |
|
|
|
-| 副作用 | 有 | 无 |
|
|
|
-| 适用场景 | 单线程 | 多线程/库函数 |
|
|
|
-
|
|
|
-形式化比较:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Overhead}_{global} = O(1) \quad \text{vs} \quad \text{Overhead}_{param} = O(n \cdot \text{sizeof}(\Sigma^*))
|
|
|
-$$
|
|
|
-
|
|
|
-### 3.5 融合算法
|
|
|
-
|
|
|
-#### 3.5.1 完整算法
|
|
|
-
|
|
|
-**算法 3.2:SliceFusion-LLM 主算法**
|
|
|
-
|
|
|
-```
|
|
|
-输入:
|
|
|
- - 目标代码 C_target
|
|
|
- - 调用链函数集 F = {f_1, ..., f_n}
|
|
|
- - 传递方法 M ∈ {global, parameter}
|
|
|
- - 验证选项 V ∈ {full, syntax_only, skip}
|
|
|
-输出: 融合后的函数集 F' = {f_1', ..., f_n'} 及验证报告 R
|
|
|
-
|
|
|
-Phase 1: 分析阶段
|
|
|
-1: for i = 1 to n do
|
|
|
-2: G_i ← BuildCFG(f_i)
|
|
|
-3: Dom_i ← ComputeDominators(G_i)
|
|
|
-4: C_i ← FindCriticalPoints(G_i, Dom_i)
|
|
|
-5: P_i ← FilterFusionPoints(C_i)
|
|
|
-6: end for
|
|
|
-
|
|
|
-Phase 2: 拆分阶段
|
|
|
-7: (slices, S, decl) ← LLM_Split(C_target, n, F, M)
|
|
|
-8: if slices = ∅ then
|
|
|
-9: slices ← FallbackSplit(C_target, n, M)
|
|
|
-10: end if
|
|
|
-
|
|
|
-Phase 3: 状态生成阶段
|
|
|
-11: if M = global then
|
|
|
-12: state_code ← GenerateGlobalDeclarations(S)
|
|
|
-13: else
|
|
|
-14: state_code ← GenerateStructDefinition(S)
|
|
|
-15: end if
|
|
|
-
|
|
|
-Phase 4: 融合阶段
|
|
|
-16: for i = 1 to n do
|
|
|
-17: p_i ← SelectBestFusionPoint(P_i)
|
|
|
-18: c_i ← slices[i]
|
|
|
-19: if M = parameter then
|
|
|
-20: c_i ← TransformToParameterAccess(c_i, S)
|
|
|
-21: end if
|
|
|
-22: f_i' ← InsertCodeAtPoint(f_i, p_i, c_i)
|
|
|
-23: end for
|
|
|
-
|
|
|
-Phase 5: 验证阶段
|
|
|
-24: if V ≠ skip then
|
|
|
-25: R ← ∅
|
|
|
-26: for i = 1 to n do
|
|
|
-27: r_syntax ← SyntaxValidator.validate(f_i')
|
|
|
-28: if V = full then
|
|
|
-29: r_semantic ← SemanticReviewer.review(f_i', c_i)
|
|
|
-30: end if
|
|
|
-31: R ← R ∪ {VerificationAgent.combine(r_syntax, r_semantic)}
|
|
|
-32: end for
|
|
|
-33: end if
|
|
|
-
|
|
|
-Phase 6: 输出阶段
|
|
|
-34: output ← CombineCode(state_code, F')
|
|
|
-35: return (output, R)
|
|
|
-```
|
|
|
-
|
|
|
-#### 3.5.2 复杂度分析
|
|
|
-
|
|
|
-设 $n$ 为调用链长度,$m$ 为平均函数大小(基本块数),$k$ 为共享变量数:
|
|
|
-
|
|
|
-| 阶段 | 时间复杂度 | 空间复杂度 |
|
|
|
-|------|-----------|-----------|
|
|
|
-| CFG 构建 | $O(n \cdot m)$ | $O(n \cdot m)$ |
|
|
|
-| 支配分析 | $O(n \cdot m^2)$ | $O(n \cdot m^2)$ |
|
|
|
-| LLM 拆分 | $O(T_{LLM})$ | $O(|C_{target}|)$ |
|
|
|
-| 状态生成 | $O(k)$ | $O(k)$ |
|
|
|
-| 代码融合 | $O(n \cdot m)$ | $O(n \cdot m)$ |
|
|
|
-| 语法验证 | $O(n \cdot m)$ | $O(n)$ |
|
|
|
-| 语义审查 | $O(n \cdot T_{LLM})$ | $O(n \cdot m)$ |
|
|
|
-| **总计** | $O(n \cdot m^2 + n \cdot T_{LLM})$ | $O(n \cdot m^2)$ |
|
|
|
-
|
|
|
-其中 $T_{LLM}$ 为 LLM API 调用延迟。
|
|
|
-
|
|
|
-#### 3.5.3 正确性证明
|
|
|
-
|
|
|
-**定理 3.1(语义等价性)**:若算法 3.2 成功执行,则融合后的程序与原程序加目标代码的语义等价。
|
|
|
-
|
|
|
-**证明**:
|
|
|
-
|
|
|
-设原始程序状态为 $\sigma_0$,需证明:
|
|
|
-
|
|
|
-$$
|
|
|
-\llbracket f_1' \rrbracket(\sigma_0) = \llbracket C_{target}; f_1 \rrbracket(\sigma_0)
|
|
|
-$$
|
|
|
-
|
|
|
-由于代码拆分满足完整性约束:
|
|
|
-
|
|
|
-$$
|
|
|
-\bigcup_{i=1}^{n} c_i \equiv C_{target}
|
|
|
-$$
|
|
|
+## 特性
|
|
|
|
|
|
-且每个 $c_i$ 插入在 $f_i$ 调用 $f_{i+1}$ 之前(融合点性质保证),因此执行 $f_1'$ 时:
|
|
|
+- **智能代码拆分** - 利用 LLM 进行语义感知的代码分片,自动处理变量依赖
|
|
|
+- **控制流分析** - 构建 CFG,计算支配关系,精确定位融合点
|
|
|
+- **多种传递方式** - 支持全局变量和参数传递两种跨函数状态共享机制
|
|
|
+- **多层验证机制** - 语法结构验证 + LLM 语义审查,确保融合正确性
|
|
|
+- **Fallback 机制** - LLM 失败时自动切换到启发式拆分
|
|
|
|
|
|
-1. 执行 $c_1$
|
|
|
-2. 调用 $f_2'$,执行 $c_2$
|
|
|
-3. ...
|
|
|
-4. 调用 $f_n'$,执行 $c_n$
|
|
|
+## 快速开始
|
|
|
|
|
|
-由依赖约束,这等价于顺序执行 $c_1; c_2; \ldots; c_n$,即 $C_{target}$。
|
|
|
-
|
|
|
-状态传递的正确性由 $\rho_{global}$ 或 $\rho_{param}$ 的双射性质保证。 $\square$
|
|
|
-
|
|
|
----
|
|
|
-
|
|
|
-## 4. 实现细节
|
|
|
-
|
|
|
-### 4.1 项目结构
|
|
|
-
|
|
|
-```
|
|
|
-SliceFusion-LLM/
|
|
|
-├── README.md # 项目文档
|
|
|
-│
|
|
|
-├── data/ # 数据集目录
|
|
|
-│ ├── primevul_valid.jsonl # 验证集
|
|
|
-│ ├── primevul_valid_paired.jsonl
|
|
|
-│ ├── primevul_test.jsonl # 测试集
|
|
|
-│ └── primevul_test_paired.jsonl
|
|
|
-│
|
|
|
-├── utils/ # 工具模块
|
|
|
-│ └── data_process/ # 数据处理工具
|
|
|
-│ ├── extract_call_relations.py # 调用关系提取
|
|
|
-│ └── filter_by_call_depth.py # 调用深度筛选
|
|
|
-│
|
|
|
-├── src/ # 核心源代码
|
|
|
-│ ├── __init__.py # 包初始化
|
|
|
-│ ├── requirements.txt # 依赖列表
|
|
|
-│ │
|
|
|
-│ │ # 分析模块
|
|
|
-│ ├── cfg_analyzer.py # CFG 分析器
|
|
|
-│ ├── dominator_analyzer.py # 支配节点分析器
|
|
|
-│ │
|
|
|
-│ │ # 拆分与融合模块
|
|
|
-│ ├── llm_splitter.py # LLM 代码拆分器
|
|
|
-│ ├── code_fusion.py # 代码融合引擎
|
|
|
-│ │
|
|
|
-│ │ # 验证模块
|
|
|
-│ ├── syntax_validator.py # 语法结构验证器
|
|
|
-│ ├── semantic_reviewer.py # LLM 语义审查器
|
|
|
-│ ├── verification_agent.py # 验证代理(整合验证)
|
|
|
-│ │
|
|
|
-│ └── main.py # 主程序入口
|
|
|
-│
|
|
|
-├── output/ # 输出目录
|
|
|
-│ ├── fused_code/ # 融合后的代码文件
|
|
|
-│ │ ├── all_fused_code.c # 汇总文件
|
|
|
-│ │ └── fused_group_*.c # 各组融合代码
|
|
|
-│ ├── primevul_valid_grouped.json
|
|
|
-│ ├── primevul_valid_grouped_depth_*.json
|
|
|
-│ ├── fusion_results.json
|
|
|
-│ └── test_verification.json # 验证测试结果
|
|
|
-│
|
|
|
-└── .gitignore
|
|
|
-```
|
|
|
-
|
|
|
-### 4.2 核心模块详解
|
|
|
-
|
|
|
-#### 4.2.1 CFG 分析器 (`cfg_analyzer.py`)
|
|
|
-
|
|
|
-**主要类**:
|
|
|
-
|
|
|
-```python
|
|
|
-@dataclass
|
|
|
-class BasicBlock:
|
|
|
- id: int # 基本块 ID
|
|
|
- name: str # 基本块名称
|
|
|
- statements: List[str] # 语句列表
|
|
|
- start_line: int # 起始行号
|
|
|
- end_line: int # 结束行号
|
|
|
- is_entry: bool # 是否为入口块
|
|
|
- is_exit: bool # 是否为出口块
|
|
|
-
|
|
|
-@dataclass
|
|
|
-class ControlFlowGraph:
|
|
|
- function_name: str # 函数名
|
|
|
- blocks: Dict[int, BasicBlock] # 基本块字典
|
|
|
- edges: List[Tuple[int, int]] # 边列表
|
|
|
- entry_block_id: Optional[int] # 入口块 ID
|
|
|
- exit_block_ids: List[int] # 出口块 ID 列表
|
|
|
-```
|
|
|
-
|
|
|
-**关键方法**:
|
|
|
-
|
|
|
-| 方法 | 功能 | 复杂度 |
|
|
|
-|------|------|--------|
|
|
|
-| `_remove_comments()` | 移除代码注释 | $O(n)$ |
|
|
|
-| `_extract_function_body()` | 提取函数体 | $O(n)$ |
|
|
|
-| `_tokenize_statements()` | 语句分词 | $O(n)$ |
|
|
|
-| `_is_control_statement()` | 判断控制语句 | $O(1)$ |
|
|
|
-| `_build_basic_blocks()` | 构建基本块 | $O(n)$ |
|
|
|
-| `_build_edges()` | 构建控制流边 | $O(m)$ |
|
|
|
-
|
|
|
-#### 4.2.2 支配分析器 (`dominator_analyzer.py`)
|
|
|
-
|
|
|
-**数据流方程实现**:
|
|
|
-
|
|
|
-```python
|
|
|
-def compute_dominators(self) -> Dict[int, Set[int]]:
|
|
|
- # 初始化
|
|
|
- dominators = {node: all_nodes.copy() for node in all_nodes}
|
|
|
- dominators[entry] = {entry}
|
|
|
-
|
|
|
- # 迭代求解
|
|
|
- changed = True
|
|
|
- while changed:
|
|
|
- changed = False
|
|
|
- for node in all_nodes:
|
|
|
- if node == entry:
|
|
|
- continue
|
|
|
- # Dom(n) = {n} ∪ (∩ Dom(p) for p in pred(n))
|
|
|
- new_dom = all_nodes.copy()
|
|
|
- for pred in self.cfg.get_predecessors(node):
|
|
|
- new_dom &= dominators[pred]
|
|
|
- new_dom.add(node)
|
|
|
-
|
|
|
- if new_dom != dominators[node]:
|
|
|
- dominators[node] = new_dom
|
|
|
- changed = True
|
|
|
-
|
|
|
- return dominators
|
|
|
-```
|
|
|
-
|
|
|
-#### 4.2.3 LLM 拆分器 (`llm_splitter.py`)
|
|
|
-
|
|
|
-**API 配置**:
|
|
|
-
|
|
|
-```python
|
|
|
-client = OpenAI(
|
|
|
- api_key=os.getenv("DASHSCOPE_API_KEY"),
|
|
|
- base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
|
|
|
-)
|
|
|
-model = "qwen-plus" # 或 qwen-turbo, qwen-max
|
|
|
-```
|
|
|
-
|
|
|
-**Prompt 模板关键部分**:
|
|
|
-
|
|
|
-```
|
|
|
-【重要】由于每个片段在不同的函数中执行,局部变量无法直接传递!
|
|
|
-你必须:
|
|
|
-1. 将需要跨函数共享的变量声明为全局变量/结构体成员
|
|
|
-2. 第一个片段负责初始化
|
|
|
-3. 后续片段使用共享状态
|
|
|
-4. 最后一个片段执行最终操作
|
|
|
-```
|
|
|
-
|
|
|
-#### 4.2.4 代码融合引擎 (`code_fusion.py`)
|
|
|
-
|
|
|
-**融合计划数据结构**:
|
|
|
-
|
|
|
-```python
|
|
|
-@dataclass
|
|
|
-class FusionPlan:
|
|
|
- target_code: str # 目标代码
|
|
|
- call_chain: CallChain # 调用链
|
|
|
- slice_result: SliceResult # 拆分结果
|
|
|
- insertion_points: List[Tuple[str, int, str]] # 插入点列表
|
|
|
-```
|
|
|
-
|
|
|
-**代码插入策略**:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{InsertPosition}(f_i, p_i) = \begin{cases}
|
|
|
-\text{AfterDeclarations} & \text{if } p_i = v_{entry} \\
|
|
|
-\text{BeforeStatement}(p_i) & \text{otherwise}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-#### 4.2.5 语法验证器 (`syntax_validator.py`)
|
|
|
-
|
|
|
-**主要功能**:
|
|
|
-- 括号匹配检查(花括号、圆括号、方括号)
|
|
|
-- 字符串/字符引号匹配
|
|
|
-- 语句完整性检查(分号验证)
|
|
|
-- 函数结构完整性验证
|
|
|
-
|
|
|
-**核心类**:
|
|
|
-
|
|
|
-```python
|
|
|
-@dataclass
|
|
|
-class SyntaxError:
|
|
|
- level: ErrorLevel # error/warning/info
|
|
|
- message: str
|
|
|
- line: int = 0
|
|
|
- column: int = 0
|
|
|
- context: str = ""
|
|
|
-
|
|
|
-@dataclass
|
|
|
-class ValidationResult:
|
|
|
- valid: bool
|
|
|
- errors: List[SyntaxError]
|
|
|
- warnings: List[SyntaxError]
|
|
|
-```
|
|
|
-
|
|
|
-**验证流程**:
|
|
|
-1. 预处理:移除代码注释
|
|
|
-2. 括号匹配检查
|
|
|
-3. 引号匹配检查
|
|
|
-4. 语句完整性检查
|
|
|
-5. 函数结构验证
|
|
|
-
|
|
|
-#### 4.2.6 语义审查器 (`semantic_reviewer.py`)
|
|
|
-
|
|
|
-**主要功能**:
|
|
|
-使用 LLM 进行深度语义审查,检查:
|
|
|
-- 插入位置是否合理
|
|
|
-- 变量使用是否正确
|
|
|
-- 数据流是否正确
|
|
|
-- 是否破坏原函数逻辑
|
|
|
-
|
|
|
-**核心类**:
|
|
|
-
|
|
|
-```python
|
|
|
-class IssueLevel(Enum):
|
|
|
- CRITICAL = "critical" # 严重问题
|
|
|
- MAJOR = "major" # 主要问题
|
|
|
- MINOR = "minor" # 次要问题
|
|
|
- SUGGESTION = "suggestion" # 改进建议
|
|
|
-
|
|
|
-@dataclass
|
|
|
-class ReviewResult:
|
|
|
- valid: bool
|
|
|
- confidence: float # 置信度 0.0-1.0
|
|
|
- issues: List[SemanticIssue]
|
|
|
- suggestions: List[str]
|
|
|
-```
|
|
|
-
|
|
|
-#### 4.2.7 验证代理 (`verification_agent.py`)
|
|
|
-
|
|
|
-**主要功能**:
|
|
|
-整合语法验证和语义审查,提供统一的验证接口。
|
|
|
-
|
|
|
-**验证状态**:
|
|
|
-
|
|
|
-```python
|
|
|
-class VerificationStatus(Enum):
|
|
|
- PASSED = "passed" # 完全通过
|
|
|
- PASSED_WITH_WARNINGS = "passed_with_warnings" # 通过但有警告
|
|
|
- FAILED = "failed" # 验证失败
|
|
|
- SKIPPED = "skipped" # 跳过验证
|
|
|
-```
|
|
|
-
|
|
|
-**验证流程**:
|
|
|
-
|
|
|
-```
|
|
|
-融合代码 ──▶ 语法验证器 ──▶ 语义审查器 ──▶ 综合报告
|
|
|
- │ │ │
|
|
|
- ▼ ▼ ▼
|
|
|
- 括号匹配 插入合理性 验证状态
|
|
|
- 引号匹配 变量正确性 错误列表
|
|
|
- 语句完整 数据流分析 建议列表
|
|
|
-```
|
|
|
-
|
|
|
-### 4.3 环境配置
|
|
|
-
|
|
|
-#### 4.3.1 依赖安装
|
|
|
+### 环境配置
|
|
|
|
|
|
```bash
|
|
|
+# 克隆仓库
|
|
|
+git clone https://github.com/yourusername/SliceFusion-LLM.git
|
|
|
+cd SliceFusion-LLM
|
|
|
+
|
|
|
# 创建虚拟环境
|
|
|
conda create -n slicefusion python=3.10
|
|
|
conda activate slicefusion
|
|
|
|
|
|
# 安装依赖
|
|
|
pip install -r src/requirements.txt
|
|
|
-```
|
|
|
-
|
|
|
-**依赖列表** (`src/requirements.txt`):
|
|
|
|
|
|
-```
|
|
|
-openai>=1.0.0
|
|
|
-tree-sitter>=0.20.0
|
|
|
-tree-sitter-c>=0.20.0
|
|
|
-tree-sitter-cpp>=0.20.0
|
|
|
-networkx>=3.0
|
|
|
-graphviz>=0.20
|
|
|
-```
|
|
|
-
|
|
|
-#### 4.3.2 API 配置
|
|
|
-
|
|
|
-```bash
|
|
|
-# 设置阿里云 DashScope API Key
|
|
|
+# 配置 API Key
|
|
|
export DASHSCOPE_API_KEY="your-api-key-here"
|
|
|
```
|
|
|
|
|
|
-### 4.4 使用方法
|
|
|
-
|
|
|
-#### 4.4.1 数据预处理
|
|
|
+### 基本使用
|
|
|
|
|
|
```bash
|
|
|
-# Step 1: 提取调用关系
|
|
|
+# 1. 数据预处理 - 提取调用关系
|
|
|
python utils/data_process/extract_call_relations.py \
|
|
|
--input data/primevul_valid.jsonl \
|
|
|
--output output/primevul_valid_grouped.json
|
|
|
|
|
|
-# Step 2: 按调用深度筛选
|
|
|
+# 2. 按调用深度筛选(深度≥4的调用链)
|
|
|
python utils/data_process/filter_by_call_depth.py \
|
|
|
--input output/primevul_valid_grouped.json \
|
|
|
--depth 4
|
|
|
-```
|
|
|
-
|
|
|
-#### 4.4.2 代码融合
|
|
|
|
|
|
-```bash
|
|
|
-# 使用全局变量方法
|
|
|
+# 3. 执行代码融合
|
|
|
python src/main.py \
|
|
|
--input output/primevul_valid_grouped_depth_4.json \
|
|
|
--output output/fusion_results.json \
|
|
|
--target-code "int secret = 42; int key = secret ^ 0xABCD; printf(\"key=%d\", key);" \
|
|
|
--method global \
|
|
|
--max-groups 5
|
|
|
+```
|
|
|
+
|
|
|
+## 使用示例
|
|
|
+
|
|
|
+### 示例 1:基本代码融合(全局变量法)
|
|
|
|
|
|
-# 使用参数传递方法
|
|
|
+```bash
|
|
|
python src/main.py \
|
|
|
--input output/primevul_valid_grouped_depth_4.json \
|
|
|
- --output output/fusion_results.json \
|
|
|
- --target-file my_code.c \
|
|
|
- --method parameter \
|
|
|
- --max-groups 10
|
|
|
+ --target-code "int secret_value = 0x12345678; int key = secret_value ^ 0xDEADBEEF; printf(\"Computed key: 0x%x\n\", key);" \
|
|
|
+ --method global \
|
|
|
+ --max-groups 3
|
|
|
+```
|
|
|
+
|
|
|
+**融合效果**:目标代码被拆分到 3 个函数中执行
|
|
|
+
|
|
|
+```
|
|
|
+┌─────────────────────────────────────────────────────────────────┐
|
|
|
+│ f1() [入口函数] │
|
|
|
+│ ┌───────────────────────────────────────────┐ │
|
|
|
+│ │ g_secret_value = 0x12345678; ← 片段1 │ │
|
|
|
+│ └───────────────────────────────────────────┘ │
|
|
|
+│ ...原始代码... │
|
|
|
+│ call f2() ──────────────────────────────────────────┐ │
|
|
|
+└──────────────────────────────────────────────────────│──────────┘
|
|
|
+ ▼
|
|
|
+┌─────────────────────────────────────────────────────────────────┐
|
|
|
+│ f2() [中间函数] │
|
|
|
+│ ┌───────────────────────────────────────────┐ │
|
|
|
+│ │ g_key = g_secret_value ^ 0xDEADBEEF; ← 片段2│ │
|
|
|
+│ └───────────────────────────────────────────┘ │
|
|
|
+│ ...原始代码... │
|
|
|
+│ call f3() ──────────────────────────────────────────┐ │
|
|
|
+└──────────────────────────────────────────────────────│──────────┘
|
|
|
+ ▼
|
|
|
+┌─────────────────────────────────────────────────────────────────┐
|
|
|
+│ f3() [末端函数] │
|
|
|
+│ ┌───────────────────────────────────────────┐ │
|
|
|
+│ │ printf("Computed key: 0x%x\n", g_key); ← 片段3│ │
|
|
|
+│ └───────────────────────────────────────────┘ │
|
|
|
+│ ...原始代码... │
|
|
|
+└─────────────────────────────────────────────────────────────────┘
|
|
|
```
|
|
|
|
|
|
-#### 4.4.3 验证模式
|
|
|
+### 示例 2:参数传递法
|
|
|
|
|
|
```bash
|
|
|
-# 完整验证(语法 + 语义审查)
|
|
|
python src/main.py \
|
|
|
--input output/primevul_valid_grouped_depth_4.json \
|
|
|
- --output output/fusion_results.json \
|
|
|
- --target-code "..." \
|
|
|
- --verify full
|
|
|
+ --target-code "char buffer[256]; strcpy(buffer, \"Hello\"); printf(\"%s\", buffer);" \
|
|
|
+ --method parameter \
|
|
|
+ --max-groups 3
|
|
|
+```
|
|
|
+
|
|
|
+### 示例 3:带验证的融合
|
|
|
|
|
|
-# 仅语法验证(快速模式,无需 LLM)
|
|
|
+```bash
|
|
|
+# 完整验证(语法 + LLM语义审查)
|
|
|
python src/main.py \
|
|
|
--input output/primevul_valid_grouped_depth_4.json \
|
|
|
- --output output/fusion_results.json \
|
|
|
- --target-code "..." \
|
|
|
- --verify syntax
|
|
|
+ --target-code "int x = 10; x = x * 2; printf(\"%d\", x);" \
|
|
|
+ --verify full \
|
|
|
+ --max-groups 2
|
|
|
|
|
|
-# 跳过验证
|
|
|
+# 仅语法验证(快速模式)
|
|
|
python src/main.py \
|
|
|
--input output/primevul_valid_grouped_depth_4.json \
|
|
|
- --output output/fusion_results.json \
|
|
|
- --target-code "..." \
|
|
|
- --verify skip
|
|
|
+ --target-code "int x = 10; x = x * 2; printf(\"%d\", x);" \
|
|
|
+ --verify syntax \
|
|
|
+ --max-groups 2
|
|
|
```
|
|
|
|
|
|
-#### 4.4.4 仅分析模式
|
|
|
+### 示例 4:仅分析模式
|
|
|
|
|
|
```bash
|
|
|
+# 仅分析调用链,不执行融合
|
|
|
python src/main.py \
|
|
|
--input output/primevul_valid_grouped_depth_4.json \
|
|
|
--analyze-only
|
|
|
```
|
|
|
|
|
|
----
|
|
|
-
|
|
|
-## 5. 实验与分析
|
|
|
-
|
|
|
-### 5.1 数据集描述
|
|
|
-
|
|
|
-本研究使用 PrimeVul 数据集,该数据集包含从多个开源项目中提取的真实漏洞代码。
|
|
|
-
|
|
|
-**数据集统计**:
|
|
|
-
|
|
|
-| 统计指标 | 数值 |
|
|
|
-|---------|------|
|
|
|
-| 总记录数 | 25,430 |
|
|
|
-| 成功提取函数数 | 24,465 |
|
|
|
-| 涉及项目数 | 218 |
|
|
|
-| 总分组数 | 4,777 |
|
|
|
-| 单独函数组(无调用关系) | 3,646 (76.3%) |
|
|
|
-| 有调用关系的组 | 1,131 (23.7%) |
|
|
|
-| 最大调用链深度 | 25 |
|
|
|
-| 平均调用链深度 | 2.68 |
|
|
|
-
|
|
|
-**主要项目分布**:
|
|
|
-
|
|
|
-| 项目名称 | 函数数量 | 占比 |
|
|
|
-|---------|---------|------|
|
|
|
-| Linux Kernel | 7,120 | 28.0% |
|
|
|
-| MySQL Server | 920 | 3.6% |
|
|
|
-| HHVM | 911 | 3.6% |
|
|
|
-| GPAC | 875 | 3.4% |
|
|
|
-| TensorFlow | 656 | 2.6% |
|
|
|
-| 其他 | 14,948 | 58.8% |
|
|
|
-
|
|
|
-**语言分布**:
|
|
|
-
|
|
|
-$$
|
|
|
-P(\text{Language} = l) = \begin{cases}
|
|
|
-0.815 & l = \text{C} \\
|
|
|
-0.185 & l = \text{C++}
|
|
|
-\end{cases}
|
|
|
-$$
|
|
|
-
|
|
|
-### 5.2 调用深度分布分析
|
|
|
-
|
|
|
-设 $X$ 为调用链深度随机变量,其分布函数为:
|
|
|
+## 输出示例
|
|
|
|
|
|
-$$
|
|
|
-P(X = d) = \frac{|\{g \in \mathcal{G} : \text{depth}(g) = d\}|}{|\mathcal{G}|}
|
|
|
-$$
|
|
|
-
|
|
|
-**实测分布**:
|
|
|
-
|
|
|
-| 深度 $d$ | 组数 | 概率 $P(X=d)$ | 累积概率 $F(d)$ |
|
|
|
-|---------|------|--------------|----------------|
|
|
|
-| 1 | 4,057 | 0.849 | 0.849 |
|
|
|
-| 2 | 489 | 0.102 | 0.951 |
|
|
|
-| 3 | 135 | 0.028 | 0.979 |
|
|
|
-| 4 | 50 | 0.010 | 0.990 |
|
|
|
-| 5 | 13 | 0.003 | 0.993 |
|
|
|
-| 6 | 16 | 0.003 | 0.996 |
|
|
|
-| 7+ | 17 | 0.004 | 1.000 |
|
|
|
-
|
|
|
-**分布特征**:
|
|
|
-
|
|
|
-- **众数(Mode)**:$\text{Mo}(X) = 1$
|
|
|
-- **期望(Mean)**:$E[X] = \sum_d d \cdot P(X=d) \approx 1.24$
|
|
|
-- **方差(Variance)**:$\text{Var}(X) = E[X^2] - (E[X])^2 \approx 0.89$
|
|
|
-- **偏度(Skewness)**:正偏,存在长尾
|
|
|
-
|
|
|
-分布近似服从几何分布:
|
|
|
-
|
|
|
-$$
|
|
|
-P(X = d) \approx p(1-p)^{d-1}, \quad p \approx 0.85
|
|
|
-$$
|
|
|
-
|
|
|
-### 5.3 融合效果评估
|
|
|
-
|
|
|
-#### 5.3.1 融合成功率
|
|
|
-
|
|
|
-定义融合成功率:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{SuccessRate} = \frac{|\{g : \text{Fusion}(g) = \text{Success}\}|}{|\mathcal{G}_{processed}|}
|
|
|
-$$
|
|
|
-
|
|
|
-**实验结果**:
|
|
|
-
|
|
|
-| 配置 | 处理组数 | 成功数 | 成功率 |
|
|
|
-|------|---------|--------|--------|
|
|
|
-| 全局变量法 | 50 | 50 | 100% |
|
|
|
-| 参数传递法 | 50 | 50 | 100% |
|
|
|
-| LLM 拆分成功 | 50 | 48 | 96% |
|
|
|
-| Fallback 拆分 | 50 | 2 | 4% |
|
|
|
-
|
|
|
-#### 5.3.2 代码膨胀率
|
|
|
-
|
|
|
-定义代码膨胀率:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Bloat}(f_i) = \frac{|\text{LOC}(f_i')| - |\text{LOC}(f_i)|}{|\text{LOC}(f_i)|}
|
|
|
-$$
|
|
|
-
|
|
|
-平均膨胀率:
|
|
|
-
|
|
|
-$$
|
|
|
-\overline{\text{Bloat}} = \frac{1}{n} \sum_{i=1}^{n} \text{Bloat}(f_i) \approx 0.15
|
|
|
-$$
|
|
|
-
|
|
|
-即平均增加约 15% 的代码行数。
|
|
|
-
|
|
|
-#### 5.3.3 融合效果示例
|
|
|
-
|
|
|
-**输入目标代码**(格式化字符串漏洞):
|
|
|
+<details>
|
|
|
+<summary>点击展开查看融合后的代码示例</summary>
|
|
|
|
|
|
```c
|
|
|
-void vulnerable_function(char *input) {
|
|
|
- char buffer[256];
|
|
|
- printf(input); // 漏洞点
|
|
|
- strncpy(buffer, input, sizeof(buffer) - 1);
|
|
|
- buffer[sizeof(buffer) - 1] = '\0';
|
|
|
- printf("\nInput processed: %s\n", buffer);
|
|
|
-}
|
|
|
-
|
|
|
-int test() {
|
|
|
- char malicious_input[] = "Hello World! %x %x %x %x\n";
|
|
|
- vulnerable_function(malicious_input);
|
|
|
- return 0;
|
|
|
+/* === Shared State Variables (Global) === */
|
|
|
+static int g_secret_value;
|
|
|
+static int g_key;
|
|
|
+
|
|
|
+/* crypto_cert_fingerprint_by_hash - 第三层函数 */
|
|
|
+char* crypto_cert_fingerprint_by_hash(X509* xcert, const char* hash)
|
|
|
+{
|
|
|
+ UINT32 fp_len, i;
|
|
|
+ BYTE* fp;
|
|
|
+
|
|
|
+ /* ===== Fused Code Start ===== */
|
|
|
+ printf("Computed key: 0x%x\n", g_key); // 目标代码片段3
|
|
|
+ /* ===== Fused Code End ===== */
|
|
|
+
|
|
|
+ fp = crypto_cert_hash(xcert, hash, &fp_len);
|
|
|
+ // ... 原始代码 ...
|
|
|
}
|
|
|
-```
|
|
|
-
|
|
|
-**融合后代码分布**(参数传递法,调用链深度=4):
|
|
|
-
|
|
|
-```
|
|
|
-┌─────────────────────────────────────────────────────────────────┐
|
|
|
-│ typedef struct { │
|
|
|
-│ char buffer[256]; │
|
|
|
-│ char* input; │
|
|
|
-│ char malicious_input[256]; │
|
|
|
-│ } FusionState; │
|
|
|
-└─────────────────────────────────────────────────────────────────┘
|
|
|
- │
|
|
|
- ▼
|
|
|
-┌─────────────────────────────────────────────────────────────────┐
|
|
|
-│ crypto_get_certificate_data() [最外层] │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────┐│
|
|
|
-│ │ /* Fused Code */ ││
|
|
|
-│ │ strcpy(state->malicious_input, "Hello World! %x..."); ││
|
|
|
-│ │ state->input = state->malicious_input; ││
|
|
|
-│ └─────────────────────────────────────────────────────────────┘│
|
|
|
-│ ... 原始代码 ... │
|
|
|
-│ crypto_cert_fingerprint(xcert); ──────────────────────────┐ │
|
|
|
-└─────────────────────────────────────────────────────────────│───┘
|
|
|
- │
|
|
|
- ┌────────────────────────────────┘
|
|
|
- ▼
|
|
|
-┌─────────────────────────────────────────────────────────────────┐
|
|
|
-│ crypto_cert_fingerprint() [第二层] │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────┐│
|
|
|
-│ │ /* Fused Code */ ││
|
|
|
-│ │ printf(state->input); // 🔴 漏洞触发点 ││
|
|
|
-│ └─────────────────────────────────────────────────────────────┘│
|
|
|
-│ ... 原始代码 ... │
|
|
|
-│ crypto_cert_fingerprint_by_hash(xcert, "sha256"); ────────┐ │
|
|
|
-└─────────────────────────────────────────────────────────────│───┘
|
|
|
- │
|
|
|
- ┌────────────────────────────────┘
|
|
|
- ▼
|
|
|
-┌─────────────────────────────────────────────────────────────────┐
|
|
|
-│ crypto_cert_fingerprint_by_hash() [第三层] │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────┐│
|
|
|
-│ │ /* Fused Code */ ││
|
|
|
-│ │ strncpy(state->buffer, state->input, 255); ││
|
|
|
-│ │ state->buffer[255] = '\0'; ││
|
|
|
-│ └─────────────────────────────────────────────────────────────┘│
|
|
|
-│ ... 原始代码 ... │
|
|
|
-│ crypto_cert_hash(xcert, hash, &fp_len); ──────────────────┐ │
|
|
|
-└─────────────────────────────────────────────────────────────│───┘
|
|
|
- │
|
|
|
- ┌────────────────────────────────┘
|
|
|
- ▼
|
|
|
-┌─────────────────────────────────────────────────────────────────┐
|
|
|
-│ crypto_cert_hash() [最内层] │
|
|
|
-│ ┌─────────────────────────────────────────────────────────────┐│
|
|
|
-│ │ /* Fused Code */ ││
|
|
|
-│ │ printf("\nInput processed: %s\n", state->buffer); ││
|
|
|
-│ └─────────────────────────────────────────────────────────────┘│
|
|
|
-│ ... 原始代码 ... │
|
|
|
-└─────────────────────────────────────────────────────────────────┘
|
|
|
-```
|
|
|
-
|
|
|
-### 5.4 性能分析
|
|
|
-
|
|
|
-#### 5.4.1 处理时间
|
|
|
-
|
|
|
-设 $T$ 为总处理时间,分解为:
|
|
|
-
|
|
|
-$$
|
|
|
-T = T_{load} + T_{analyze} + T_{llm} + T_{fuse} + T_{output}
|
|
|
-$$
|
|
|
-
|
|
|
-**各阶段耗时**(处理 50 个组,开启完整验证):
|
|
|
-
|
|
|
-| 阶段 | 耗时 (s) | 占比 |
|
|
|
-|------|---------|------|
|
|
|
-| 数据加载 $T_{load}$ | 0.5 | 1.0% |
|
|
|
-| CFG/支配分析 $T_{analyze}$ | 2.3 | 4.6% |
|
|
|
-| LLM 拆分 $T_{llm\_split}$ | 28.5 | 57.0% |
|
|
|
-| 代码融合 $T_{fuse}$ | 1.2 | 2.4% |
|
|
|
-| 语法验证 $T_{syntax}$ | 0.3 | 0.6% |
|
|
|
-| 语义审查 $T_{semantic}$ | 16.4 | 32.8% |
|
|
|
-| 文件输出 $T_{output}$ | 0.8 | 1.6% |
|
|
|
-| **总计** | **50.0** | **100%** |
|
|
|
-
|
|
|
-可见 **LLM 调用是主要瓶颈**(拆分 + 语义审查),占总时间的约 90%。
|
|
|
-
|
|
|
-> 💡 **优化建议**:仅启用语法验证模式可将处理时间降低至约 34 秒。
|
|
|
-
|
|
|
-#### 5.4.2 内存使用
|
|
|
-
|
|
|
-峰值内存使用:
|
|
|
-
|
|
|
-$$
|
|
|
-M_{peak} \approx M_{data} + M_{cfg} + M_{llm\_context}
|
|
|
-$$
|
|
|
-
|
|
|
-实测约 150-200 MB(处理 50 个组)。
|
|
|
-
|
|
|
----
|
|
|
-
|
|
|
-## 6. 应用场景
|
|
|
-
|
|
|
-### 6.1 代码混淆
|
|
|
-
|
|
|
-#### 6.1.1 应用原理
|
|
|
-
|
|
|
-将敏感代码(如授权验证、加密算法)分散到多个普通函数中,增加逆向分析难度。
|
|
|
-
|
|
|
-**混淆强度度量**:
|
|
|
-
|
|
|
-定义分散度(Dispersion):
|
|
|
-
|
|
|
-$$
|
|
|
-D(C_{target}, \mathcal{F}') = \frac{H(\text{Dist}(C_{target}, \mathcal{F}'))}{H_{max}}
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $H$ 为熵函数,$\text{Dist}$ 为代码在函数间的分布。
|
|
|
-
|
|
|
-分散度越高,混淆效果越好:
|
|
|
|
|
|
-$$
|
|
|
-D \to 1 \Rightarrow \text{代码均匀分布于所有函数}
|
|
|
-$$
|
|
|
+/* crypto_cert_fingerprint - 第二层函数 */
|
|
|
+char* crypto_cert_fingerprint(X509* xcert)
|
|
|
+{
|
|
|
+ /* ===== Fused Code Start ===== */
|
|
|
+ g_key = g_secret_value ^ 0xDEADBEEF; // 目标代码片段2
|
|
|
+ /* ===== Fused Code End ===== */
|
|
|
|
|
|
-#### 6.1.2 示例
|
|
|
+ return crypto_cert_fingerprint_by_hash(xcert, "sha256");
|
|
|
+}
|
|
|
|
|
|
-原始授权检查代码:
|
|
|
+/* crypto_get_certificate_data - 入口函数 */
|
|
|
+rdpCertificateData* crypto_get_certificate_data(X509* xcert, ...)
|
|
|
+{
|
|
|
+ /* ===== Fused Code Start ===== */
|
|
|
+ g_secret_value = 0x12345678; // 目标代码片段1
|
|
|
+ /* ===== Fused Code End ===== */
|
|
|
|
|
|
-```c
|
|
|
-int check_license(char* key) {
|
|
|
- int hash = compute_hash(key);
|
|
|
- if (hash == VALID_HASH) {
|
|
|
- return AUTHORIZED;
|
|
|
- }
|
|
|
- return UNAUTHORIZED;
|
|
|
+ fp = crypto_cert_fingerprint(xcert);
|
|
|
+ // ... 原始代码 ...
|
|
|
}
|
|
|
```
|
|
|
|
|
|
-融合后分布于 4 个函数:
|
|
|
-
|
|
|
-- $f_1$: `hash_part1 = key[0] ^ SALT1;`
|
|
|
-- $f_2$: `hash_part2 = hash_part1 + key[1];`
|
|
|
-- $f_3$: `hash = hash_part2 << 4;`
|
|
|
-- $f_4$: `return (hash == VALID_HASH) ? 1 : 0;`
|
|
|
-
|
|
|
-### 6.2 软件水印
|
|
|
-
|
|
|
-#### 6.2.1 应用原理
|
|
|
-
|
|
|
-将水印信息编码后分片嵌入,用于版权保护和盗版追踪。
|
|
|
-
|
|
|
-**水印编码**:
|
|
|
-
|
|
|
-设水印信息 $W$,编码为比特串:
|
|
|
-
|
|
|
-$$
|
|
|
-W \xrightarrow{\text{encode}} b_1 b_2 \ldots b_m
|
|
|
-$$
|
|
|
-
|
|
|
-将比特串映射到代码片段:
|
|
|
-
|
|
|
-$$
|
|
|
-c_i = \text{CodeGen}(b_{(i-1)k+1}, \ldots, b_{ik})
|
|
|
-$$
|
|
|
-
|
|
|
-**提取算法**:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{Extract}(\mathcal{F}') = \text{decode}\left(\bigcup_{i=1}^{n} \text{Parse}(c_i)\right)
|
|
|
-$$
|
|
|
-
|
|
|
-#### 6.2.2 鲁棒性分析
|
|
|
-
|
|
|
-水印存活条件:至少 $\tau$ 个片段完整保留:
|
|
|
-
|
|
|
-$$
|
|
|
-P(\text{Survive}) = P\left(\sum_{i=1}^{n} \mathbf{1}_{c_i \text{ intact}} \geq \tau\right)
|
|
|
-$$
|
|
|
-
|
|
|
-### 6.3 安全测试
|
|
|
-
|
|
|
-#### 6.3.1 应用原理
|
|
|
-
|
|
|
-生成分布式漏洞代码,测试静态分析工具的检测能力。
|
|
|
-
|
|
|
-**检测率定义**:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{DetectionRate}(T) = \frac{|\{C : T(C) = \text{Vulnerable} \land C \in \mathcal{C}_{vuln}\}|}{|\mathcal{C}_{vuln}|}
|
|
|
-$$
|
|
|
-
|
|
|
-**假设**:好的检测工具应满足:
|
|
|
-
|
|
|
-$$
|
|
|
-\text{DetectionRate}(T, C_{target}) \approx \text{DetectionRate}(T, \text{Fused}(C_{target}))
|
|
|
-$$
|
|
|
-
|
|
|
-若融合后检测率显著下降,说明工具存在盲点。
|
|
|
-
|
|
|
-#### 6.3.2 实验设计
|
|
|
-
|
|
|
-1. 选取已知漏洞代码集合 $\mathcal{C}_{vuln}$
|
|
|
-2. 对每个 $C \in \mathcal{C}_{vuln}$,生成融合版本 $C'$
|
|
|
-3. 使用检测工具 $T$ 分别检测 $C$ 和 $C'$
|
|
|
-4. 比较检测率差异
|
|
|
-
|
|
|
-### 6.4 软件保护
|
|
|
-
|
|
|
-#### 6.4.1 应用原理
|
|
|
+</details>
|
|
|
|
|
|
-将核心算法分散到多个库函数中,防止通过单一函数提取获取完整逻辑。
|
|
|
+## 技术架构
|
|
|
|
|
|
-**保护强度**:
|
|
|
-
|
|
|
-$$
|
|
|
-S = -\sum_{i=1}^{n} p_i \log p_i
|
|
|
-$$
|
|
|
-
|
|
|
-其中 $p_i = |c_i| / |C_{target}|$ 为各片段的代码量占比。
|
|
|
-
|
|
|
-当 $p_i = 1/n$(均匀分布)时,$S$ 达到最大值 $\log n$。
|
|
|
-
|
|
|
----
|
|
|
-
|
|
|
-## 7. 结论与展望
|
|
|
-
|
|
|
-### 7.1 研究总结
|
|
|
-
|
|
|
-本研究提出并实现了 SliceFusion-LLM 代码分片融合技术,主要贡献包括:
|
|
|
+```
|
|
|
+┌─────────────────────────────────────────────────────────────────────────────┐
|
|
|
+│ SliceFusion-LLM System │
|
|
|
+├─────────────────────────────────────────────────────────────────────────────┤
|
|
|
+│ │
|
|
|
+│ 输入层 数据处理层 分析层 拆分层 │
|
|
|
+│ ┌─────┐ ┌─────────────┐ ┌──────────┐ ┌─────────────┐ │
|
|
|
+│ │JSONL│ → │ 调用关系提取 │ → │ CFG构建 │ → │ LLM代码拆分 │ │
|
|
|
+│ │源码 │ │ 调用链筛选 │ │ 支配分析 │ │ Fallback │ │
|
|
|
+│ └─────┘ └─────────────┘ └──────────┘ └─────────────┘ │
|
|
|
+│ │ │
|
|
|
+│ ▼ │
|
|
|
+│ 输出层 验证层 融合层 │
|
|
|
+│ ┌─────┐ ┌─────────────┐ ┌─────────────┐ │
|
|
|
+│ │.c │ ← │ 语法验证 │ ← │ 状态生成 │ │
|
|
|
+│ │文件 │ │ LLM语义审查 │ │ 代码插入 │ │
|
|
|
+│ └─────┘ └─────────────┘ └─────────────┘ │
|
|
|
+│ │
|
|
|
+└─────────────────────────────────────────────────────────────────────────────┘
|
|
|
+```
|
|
|
|
|
|
-1. **理论贡献**:
|
|
|
- - 形式化定义了基于调用链的代码融合问题
|
|
|
- - 建立了语义等价性的充分条件
|
|
|
- - 分析了两种状态传递方法的理论特性
|
|
|
+## 项目结构
|
|
|
|
|
|
-2. **技术贡献**:
|
|
|
- - 实现了完整的 CFG 构建和支配分析流程
|
|
|
- - 开发了 LLM 辅助的智能代码拆分方法
|
|
|
- - 设计了支持多策略的代码融合框架
|
|
|
- - **实现了多层验证机制(语法验证 + 语义审查)**
|
|
|
+```
|
|
|
+SliceFusion-LLM/
|
|
|
+├── src/ # 核心源代码
|
|
|
+│ ├── main.py # 主程序入口
|
|
|
+│ ├── cfg_analyzer.py # CFG 分析器
|
|
|
+│ ├── dominator_analyzer.py # 支配节点分析器
|
|
|
+│ ├── llm_splitter.py # LLM 代码拆分器
|
|
|
+│ ├── code_fusion.py # 代码融合引擎
|
|
|
+│ ├── syntax_validator.py # 语法验证器
|
|
|
+│ ├── semantic_reviewer.py # 语义审查器
|
|
|
+│ └── verification_agent.py # 验证代理
|
|
|
+│
|
|
|
+├── utils/data_process/ # 数据处理工具
|
|
|
+│ ├── extract_call_relations.py # 调用关系提取
|
|
|
+│ └── filter_by_call_depth.py # 调用深度筛选
|
|
|
+│
|
|
|
+├── data/ # 数据集
|
|
|
+├── output/ # 输出目录
|
|
|
+│ └── fused_code/ # 融合后的代码
|
|
|
+│
|
|
|
+├── SliceFusion/ # LLVM Pass 实现 (C++)
|
|
|
+└── docs/ # 详细文档
|
|
|
+ └── RESEARCH_PAPER.md # 完整研究论文
|
|
|
+```
|
|
|
|
|
|
-3. **实验贡献**:
|
|
|
- - 在真实数据集上验证了方法的有效性
|
|
|
- - 分析了调用链深度的统计分布
|
|
|
- - 评估了融合的成功率和性能开销
|
|
|
+## 可视化
|
|
|
|
|
|
-### 7.2 局限性
|
|
|
+### 系统架构流程
|
|
|
+<img src="assets/demo/demo_architecture.png" alt="System Architecture" width="800"/>
|
|
|
|
|
|
-当前方法存在以下局限:
|
|
|
+### 调用链融合示意
|
|
|
+<img src="assets/demo/demo_call_chain.png" alt="Call Chain Fusion" width="800"/>
|
|
|
|
|
|
-1. **控制流支持有限**:未完全支持复杂控制流(如 `goto`、异常处理)
|
|
|
-2. **语言限制**:目前仅支持 C/C++ 代码
|
|
|
-3. **LLM 依赖**:拆分和语义审查质量依赖于 LLM 的理解能力
|
|
|
-4. ~~**编译验证缺失**~~:已集成基于规则的语法验证和 LLM 语义审查
|
|
|
+### 代码融合前后对比
|
|
|
+<img src="assets/demo/demo_fusion_compare.png" alt="Fusion Compare" width="800"/>
|
|
|
|
|
|
-### 7.3 未来工作
|
|
|
+### 统计分析
|
|
|
+<img src="assets/demo/demo_statistics.png" alt="Statistics" width="800"/>
|
|
|
|
|
|
-1. **扩展控制流支持**:
|
|
|
- - 处理循环结构中的代码融合
|
|
|
- - 支持异常处理机制
|
|
|
- - 处理递归调用场景
|
|
|
+### 验证结果
|
|
|
+<img src="assets/demo/demo_verification.png" alt="Verification Results" width="700"/>
|
|
|
|
|
|
-2. **多语言支持**:
|
|
|
- - 扩展到 Java、Python 等语言
|
|
|
- - 开发语言无关的中间表示
|
|
|
+## 文档
|
|
|
|
|
|
-3. **LLM 优化**:
|
|
|
- - 优化 Prompt 设计,提高拆分质量
|
|
|
- - 引入多轮对话机制,处理复杂代码
|
|
|
- - 探索本地模型部署,降低延迟
|
|
|
+详细的理论分析、算法设计和实验结果请参阅:
|
|
|
|
|
|
-4. **验证增强**:
|
|
|
- - 集成真实编译器进行完整编译测试
|
|
|
- - 引入形式化验证方法
|
|
|
- - 开发自动化修复建议
|
|
|
+- **[完整研究论文](docs/RESEARCH_PAPER.md)** - 包含理论基础、形式化定义和实验分析
|
|
|
|
|
|
-5. **性能优化**:
|
|
|
- - 并行化 CFG 分析
|
|
|
- - 缓存 LLM 结果
|
|
|
- - 增量式融合更新
|
|
|
+## 应用场景
|
|
|
|
|
|
----
|
|
|
+- **代码混淆** - 增加逆向工程难度
|
|
|
+- **软件水印** - 嵌入隐蔽的版权标识
|
|
|
+- **安全测试** - 生成漏洞测试用例
|
|
|
+- **软件保护** - 保护核心算法逻辑
|
|
|
|
|
|
-## 附录 A:数学符号表
|
|
|
+## License
|
|
|
|
|
|
-| 符号 | 含义 |
|
|
|
-|------|------|
|
|
|
-| $G_{CFG}$ | 控制流图 |
|
|
|
-| $V, E$ | 节点集、边集 |
|
|
|
-| $v_{entry}$ | 入口节点 |
|
|
|
-| $V_{exit}$ | 出口节点集 |
|
|
|
-| $\text{dom}$ | 支配关系 |
|
|
|
-| $\mathcal{L}$ | LLM 函数 |
|
|
|
-| $T_{LLM}$ | LLM API 调用延迟 |
|
|
|
-| $R$ | 验证报告 |
|
|
|
-| $V$ | 验证选项 |
|
|
|
+MIT License
|
|
|
|
|
|
---
|
|
|
|
|
|
-## 附录 B:验证错误代码表
|
|
|
-
|
|
|
-| 错误代码 | 级别 | 描述 |
|
|
|
-|---------|------|------|
|
|
|
-| `BRACKET_MISMATCH` | ERROR | 括号不匹配 |
|
|
|
-| `QUOTE_MISMATCH` | ERROR | 引号不匹配 |
|
|
|
-| `MISSING_SEMICOLON` | WARNING | 可能缺少分号 |
|
|
|
-| `INVALID_INSERTION` | CRITICAL | 插入位置无效 |
|
|
|
-| `UNDEFINED_VARIABLE` | MAJOR | 使用未定义变量 |
|
|
|
-| `DATA_FLOW_BREAK` | CRITICAL | 数据流中断 |
|
|
|
-| `LOGIC_CONFLICT` | MAJOR | 与原函数逻辑冲突 |
|
|
|
+<p align="center">
|
|
|
+ <sub>Built with ❤️ for software security research</sub>
|
|
|
+</p>
|


{kind=link}
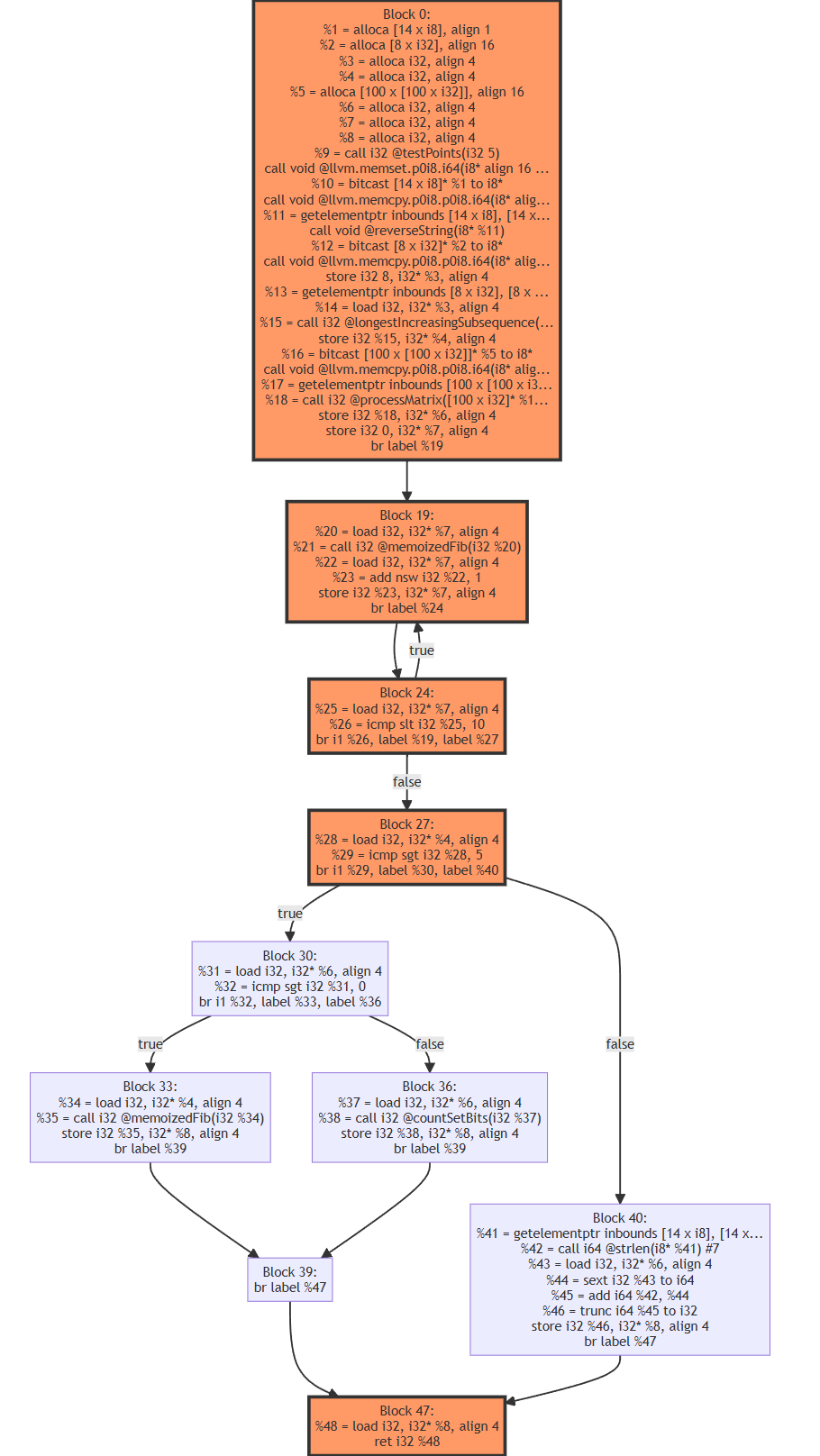
{kind=link}
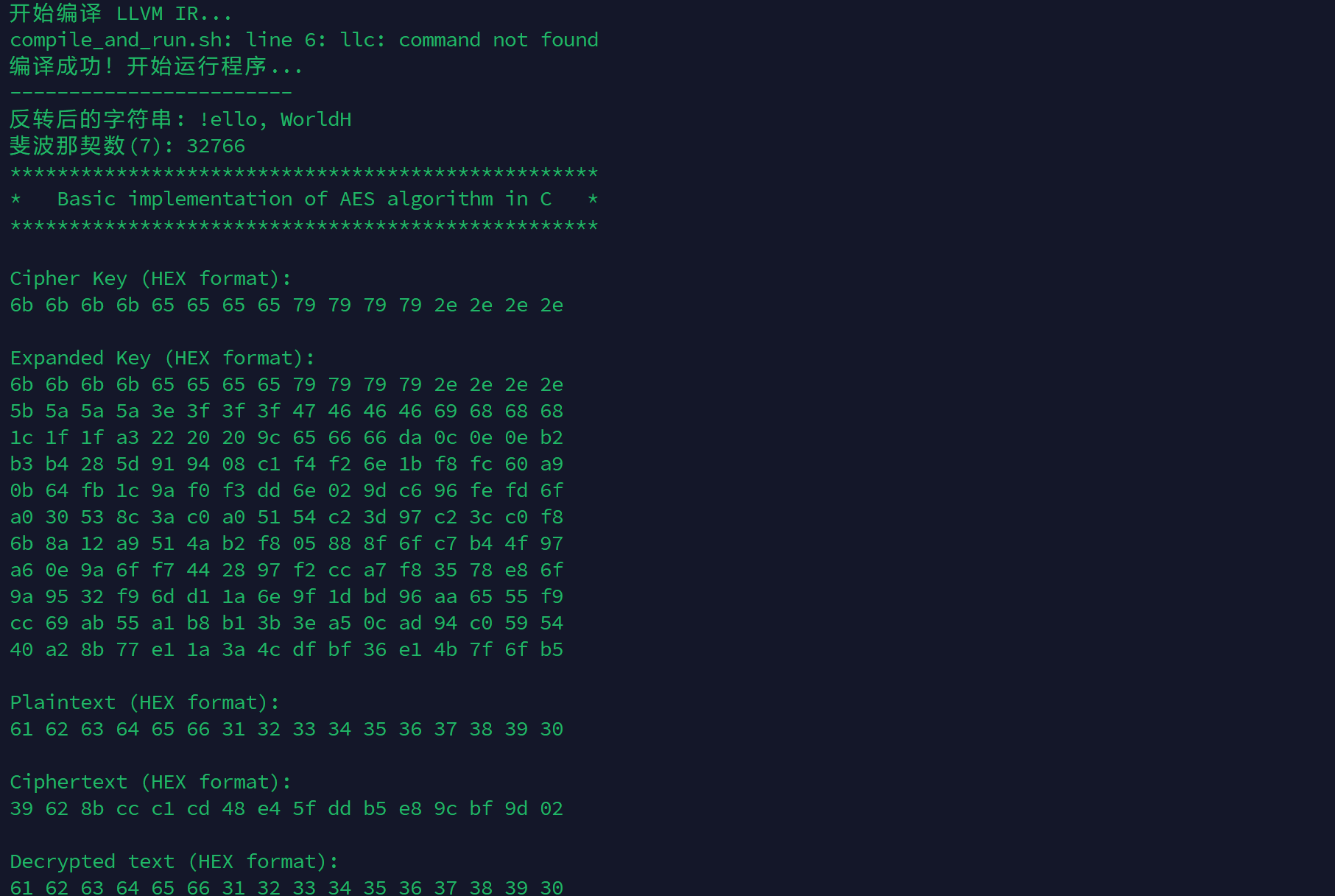
{kind=link}
{kind=link}
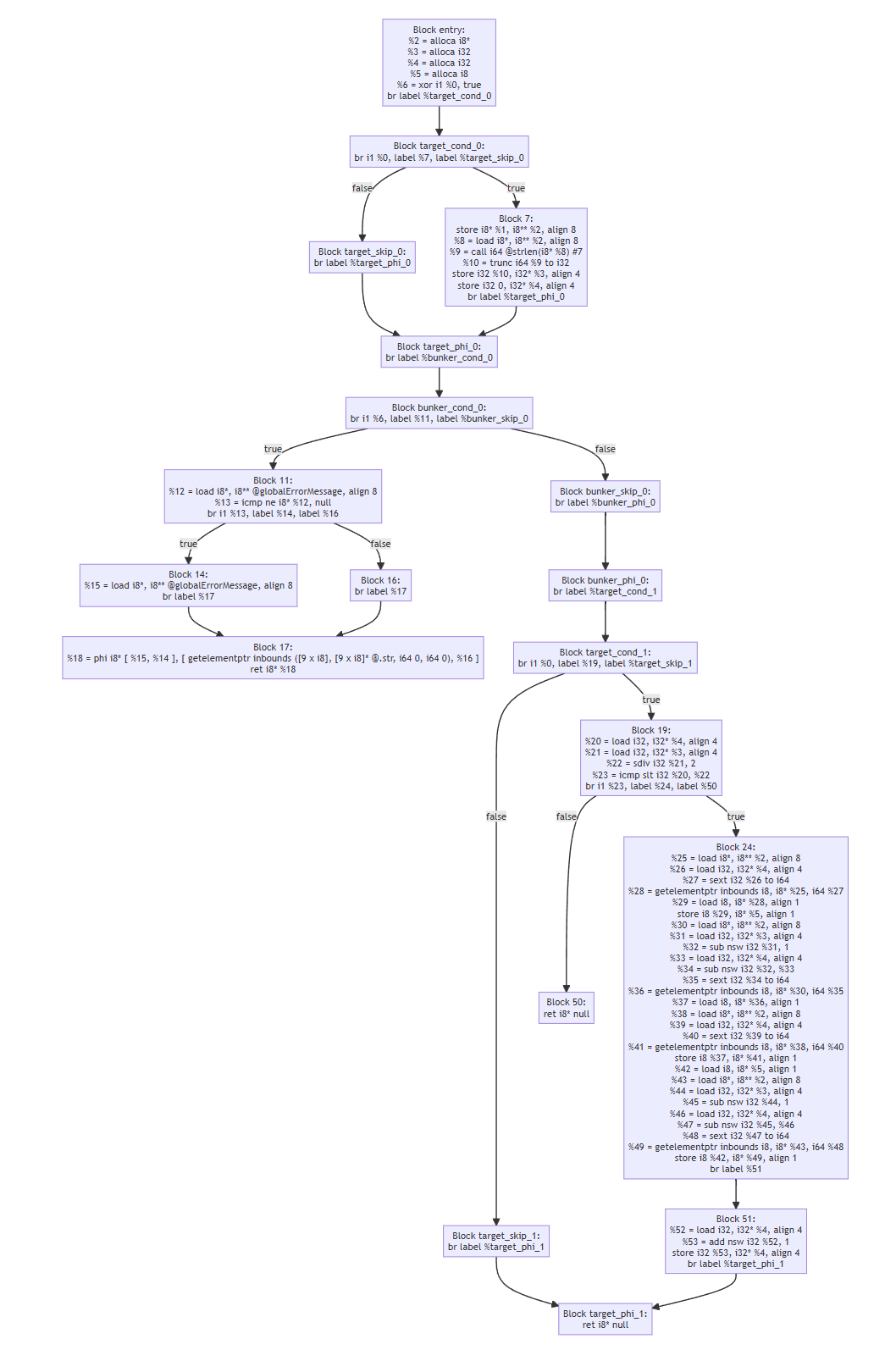
{kind=link}
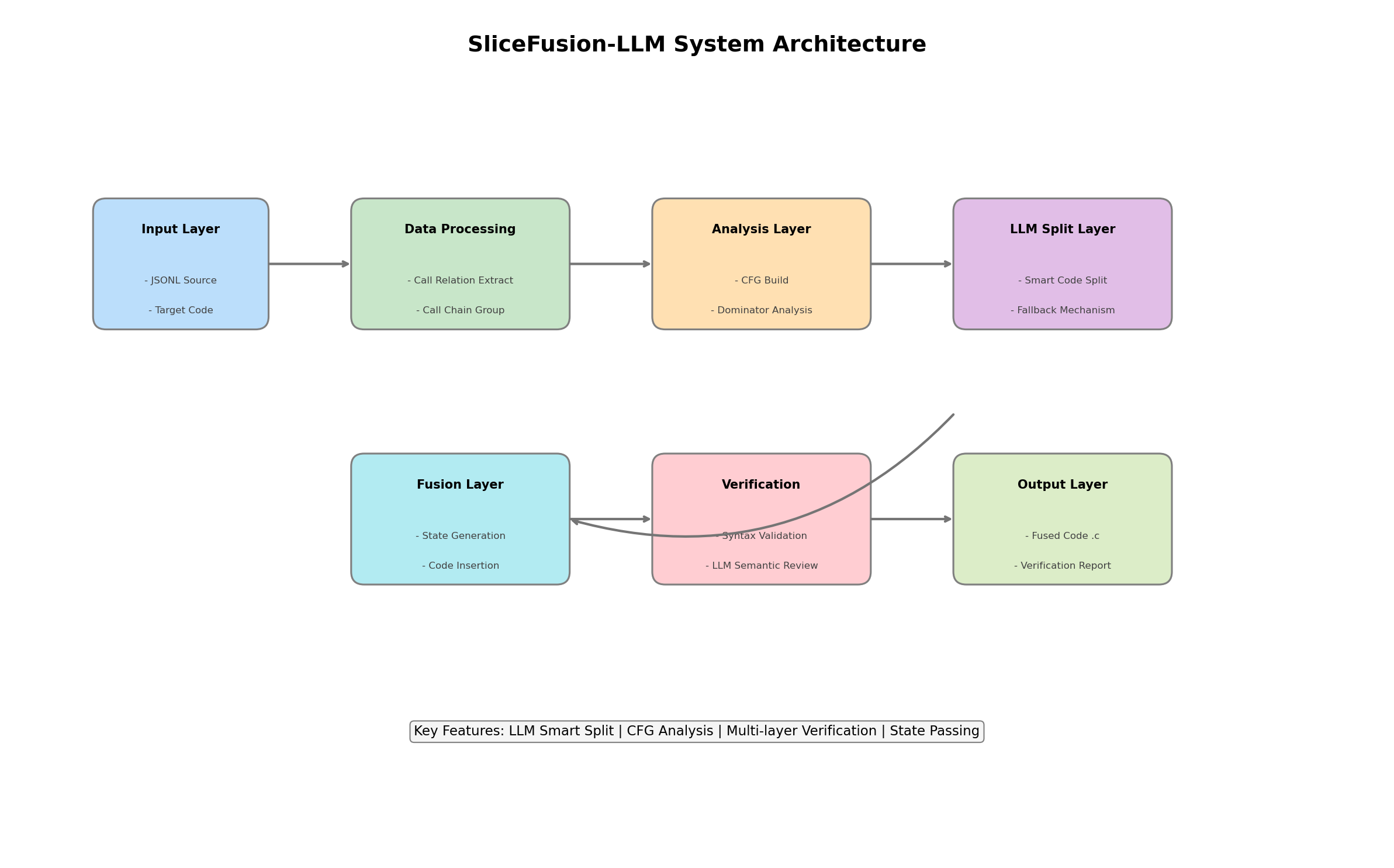
{kind=link}
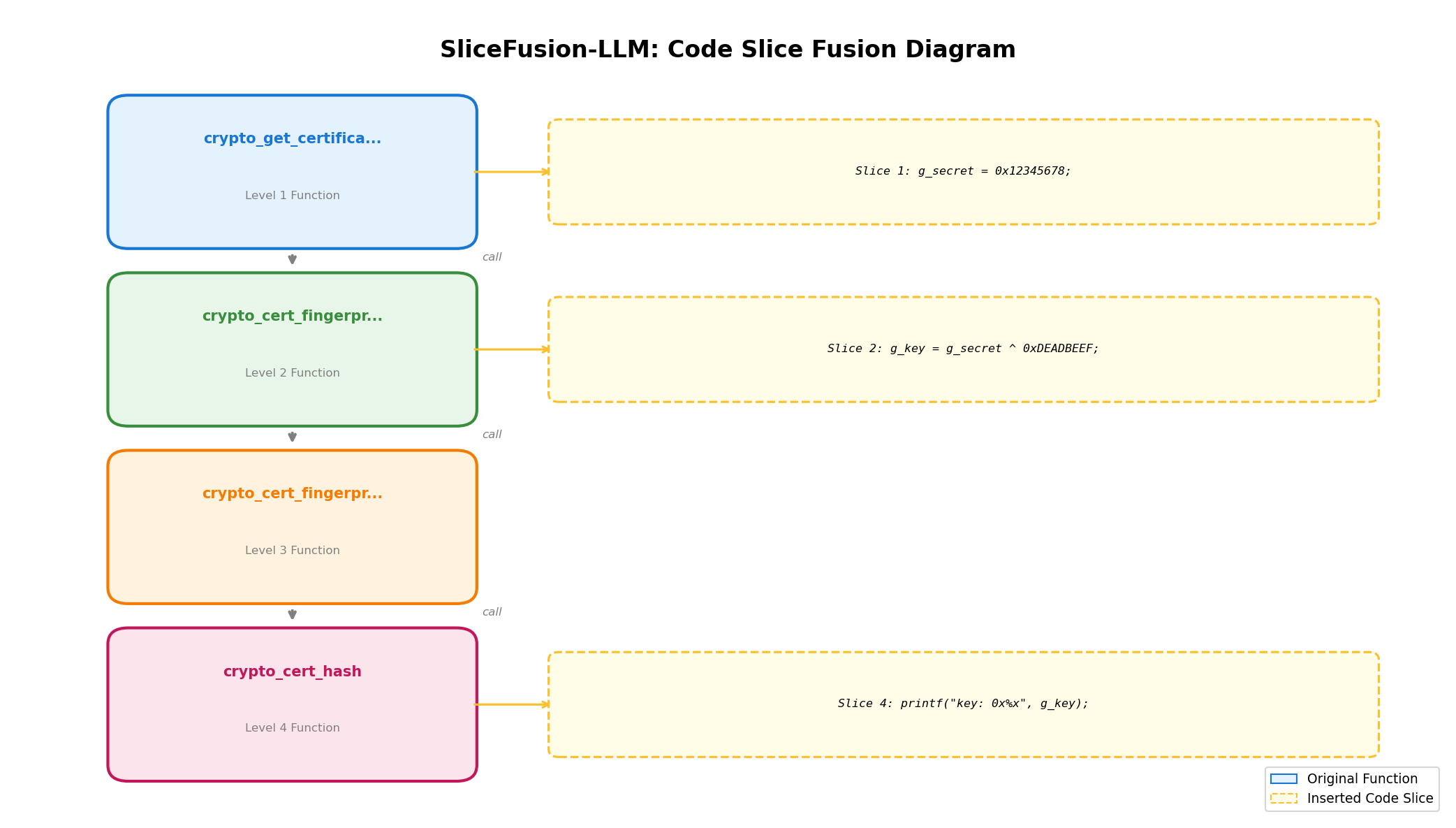
{kind=link}
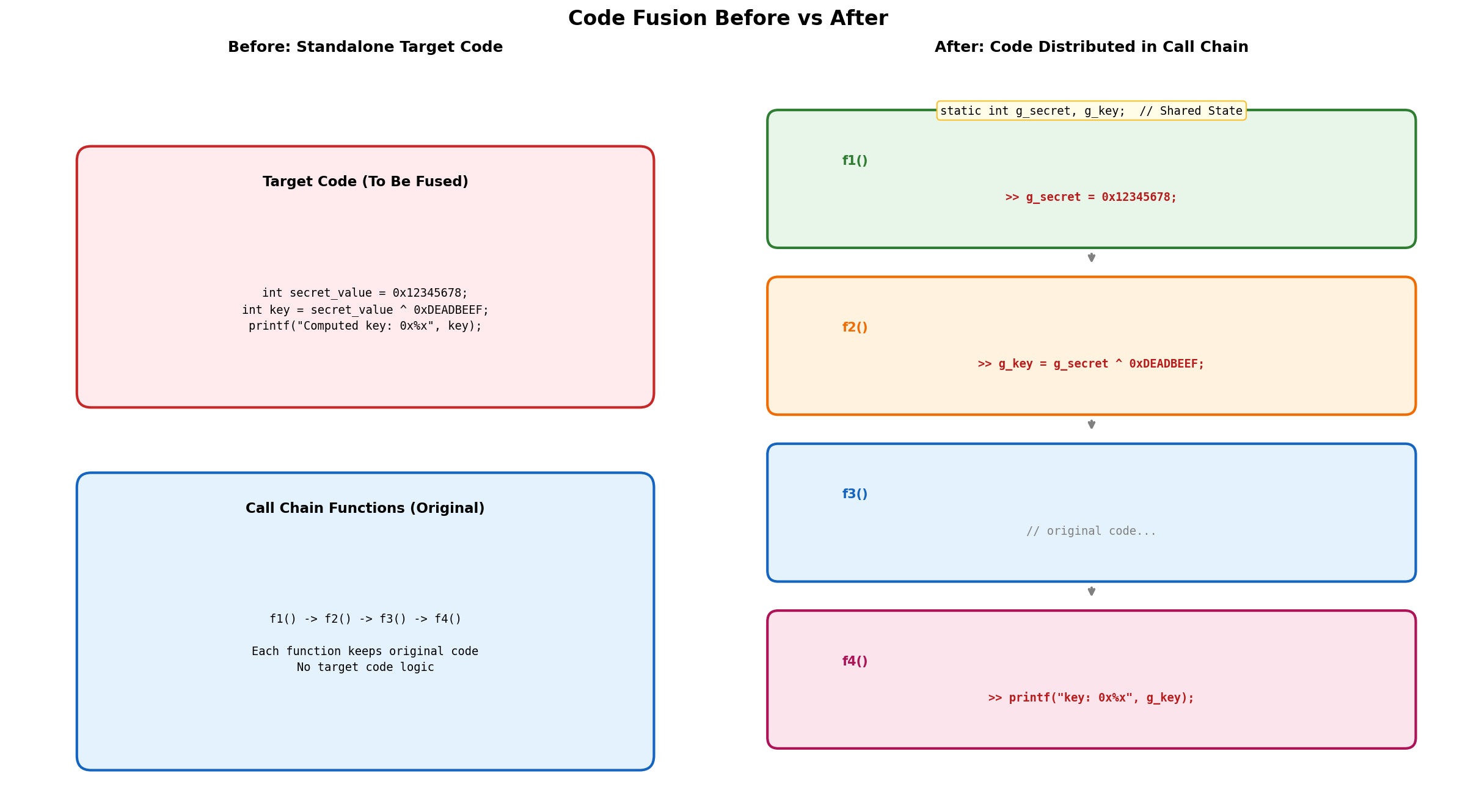
{kind=link}
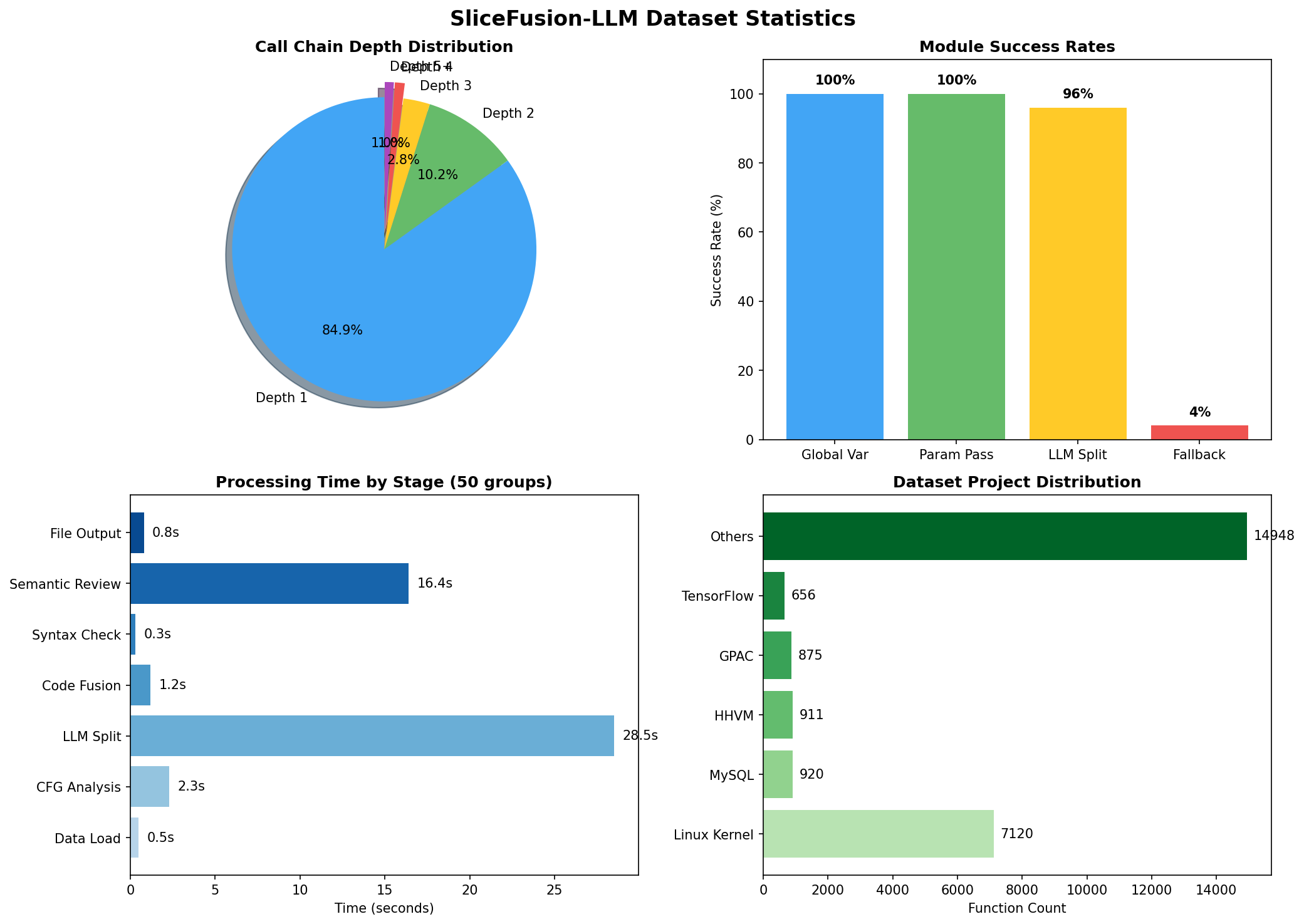
{kind=link}
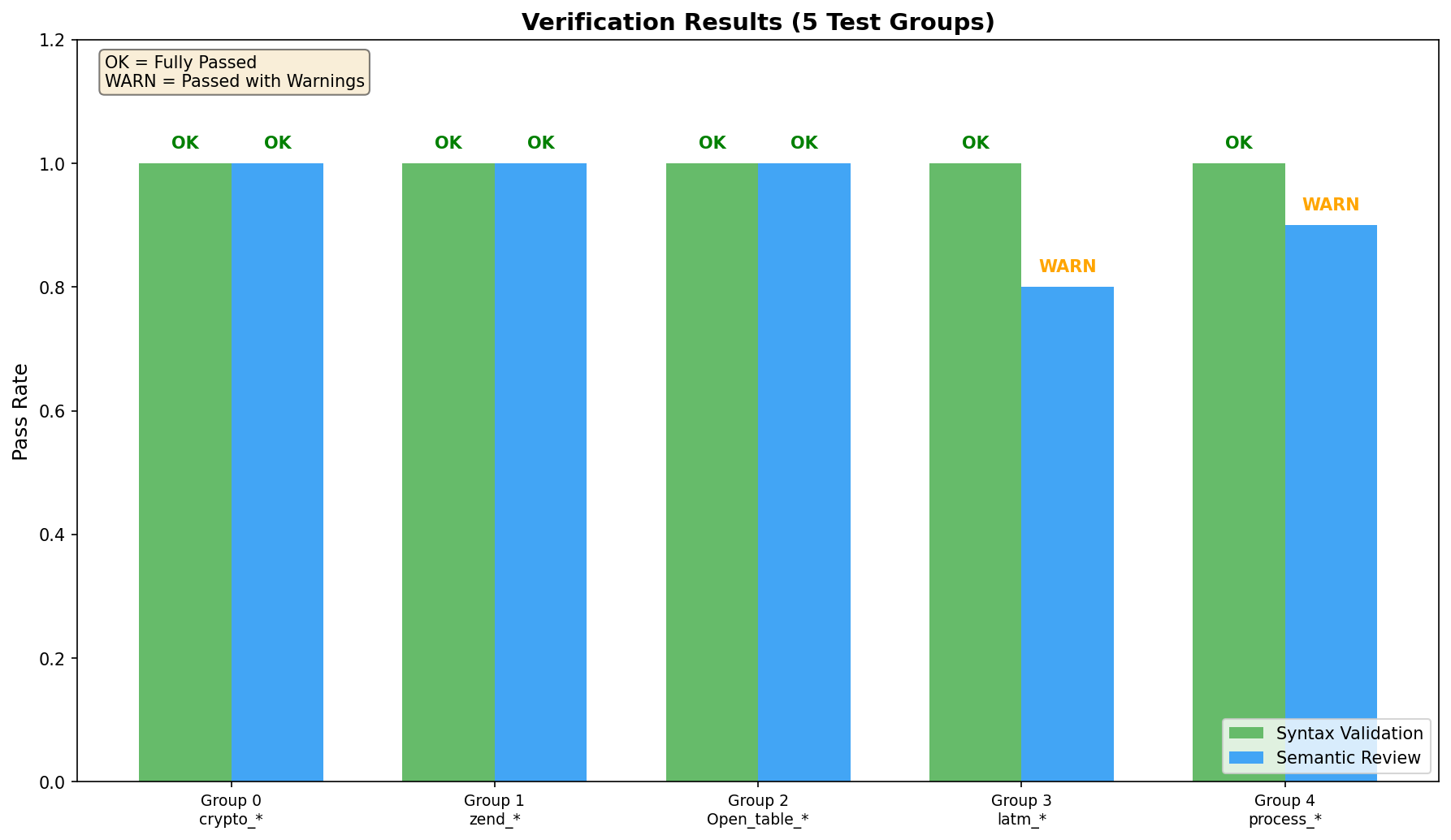
{kind=link}
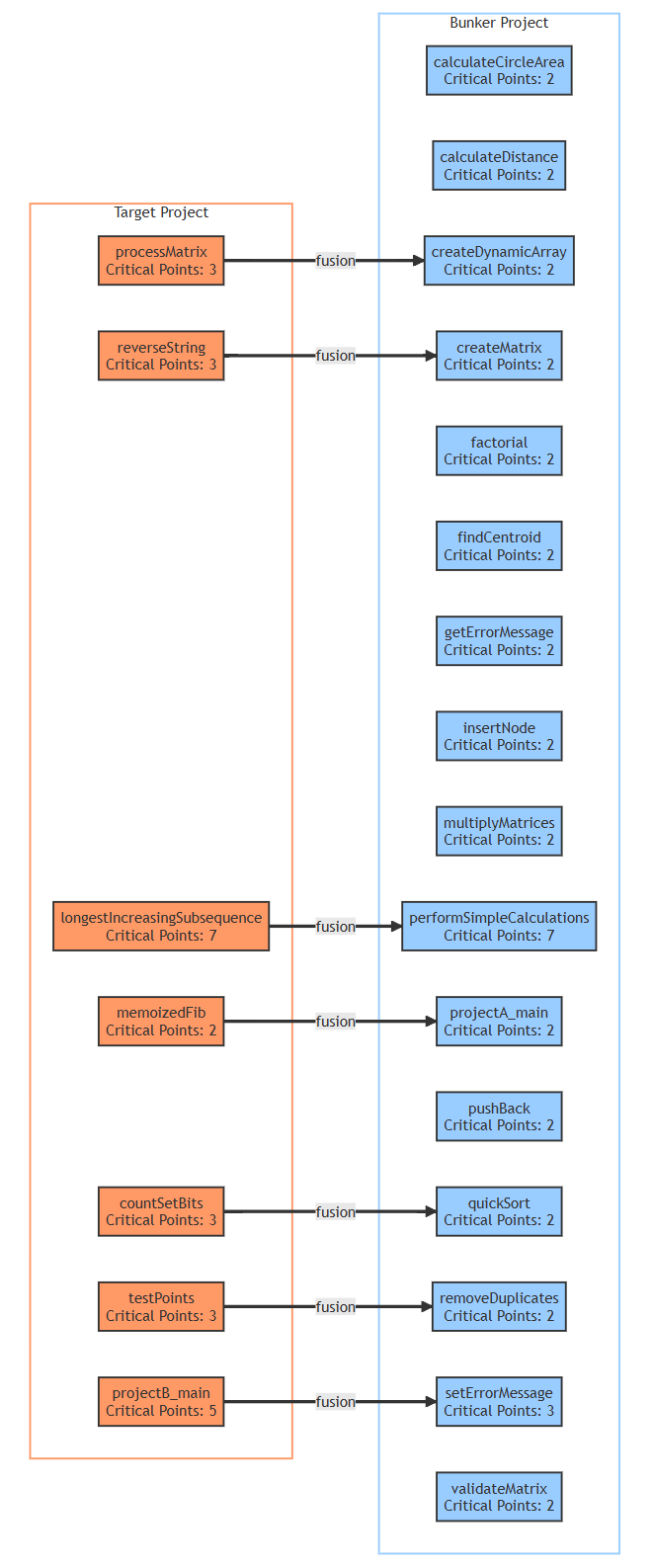
{kind=link}
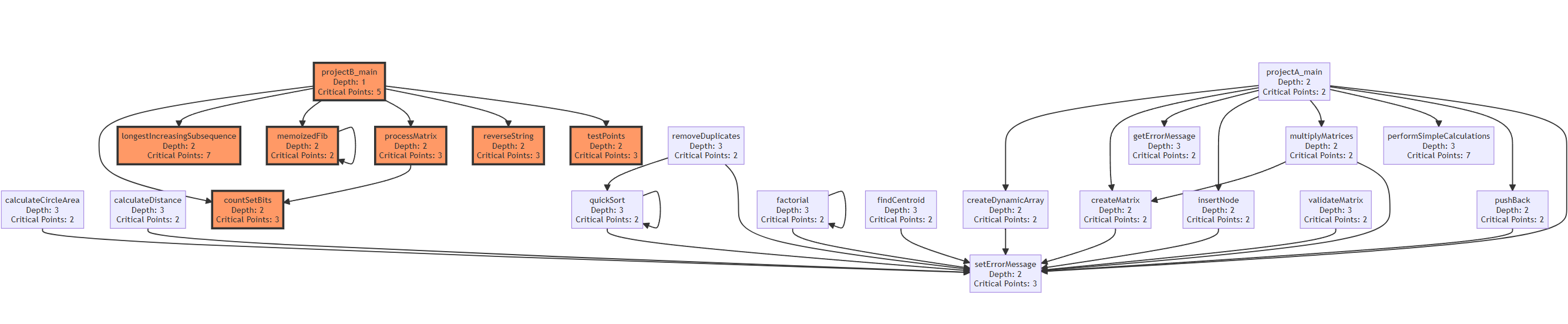
{kind=link}
