
adversarial-attack-from-leakage
 Jiaqi0602
a6d045501f
modify readme
Jiaqi0602
a6d045501f
modify readme
|
il y a 4 ans | |
|---|---|---|
| data | il y a 4 ans | |
| image | il y a 4 ans | |
| inversefed | il y a 4 ans | |
| output_rec_images | il y a 4 ans | |
| utils | il y a 4 ans | |
| .gitignore | il y a 4 ans | |
| README.md | il y a 4 ans | |
| demo - CIFAR10.ipynb | il y a 4 ans | |
| demo - VGGFACE2.ipynb | il y a 4 ans | |
| main.py | il y a 4 ans |
README.md
From Gradient Leakage to Adversarial Attacks in Federated Learning
By utilizing an existing privacy breaking algorithm which inverts gradients of models to reconstruct the input data, the data reconstructed from inverting gradients algorithm reveals the vulnerabilities of models in representation learning.
In this work, we utilize the inverting gradients algorithm proposed in Inverting Gradients - How easy is it to break Privacy in Federated Learning? to reconstruct the data that could lead to possible threats in classification task. By stacking one wrongly predicted image into different batch sizes, then use the stacked images as input of the existing gradients inverting algorithm will result in reconstruction of distorted images that can be correctly predicted by the attacked model.

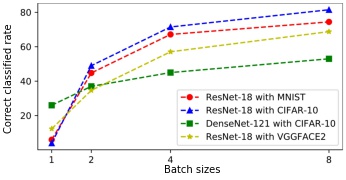
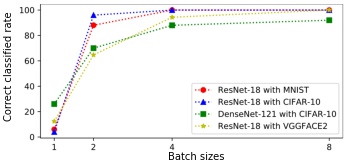
Prerequisites
Required libraries:
Python>=3.7
pytorch=1.5.0
torchvision=0.6.0
Code
python main.py --model "resnet18" --data "cifar10" stack_size 4 -ls 1001,770,123 --save True --gpu True
Implementation for ResNet-18 trained with CIFAR10 can be found HERE and with VGGFACE2 can be found HERE
Quick reproduction for CIFAR10 dataset:
You can download pretrained model from HERE then replace the torchvision models.