
 Zhuang Weiming
0d3f2d624a
[Doc]: Update FedReID README (#13)
Zhuang Weiming
0d3f2d624a
[Doc]: Update FedReID README (#13)
|
před 2 roky | |
|---|---|---|
| .. | ||
| images | před 2 roky | |
| README.md | před 2 roky | |
| __init__.py | před 2 roky | |
| client.py | před 2 roky | |
| config.yaml | před 2 roky | |
| dataset.py | před 2 roky | |
| evaluate.py | před 2 roky | |
| main.py | před 2 roky | |
| model.py | před 2 roky | |
| remote_client.py | před 2 roky | |
| remote_server.py | před 2 roky | |
README.md
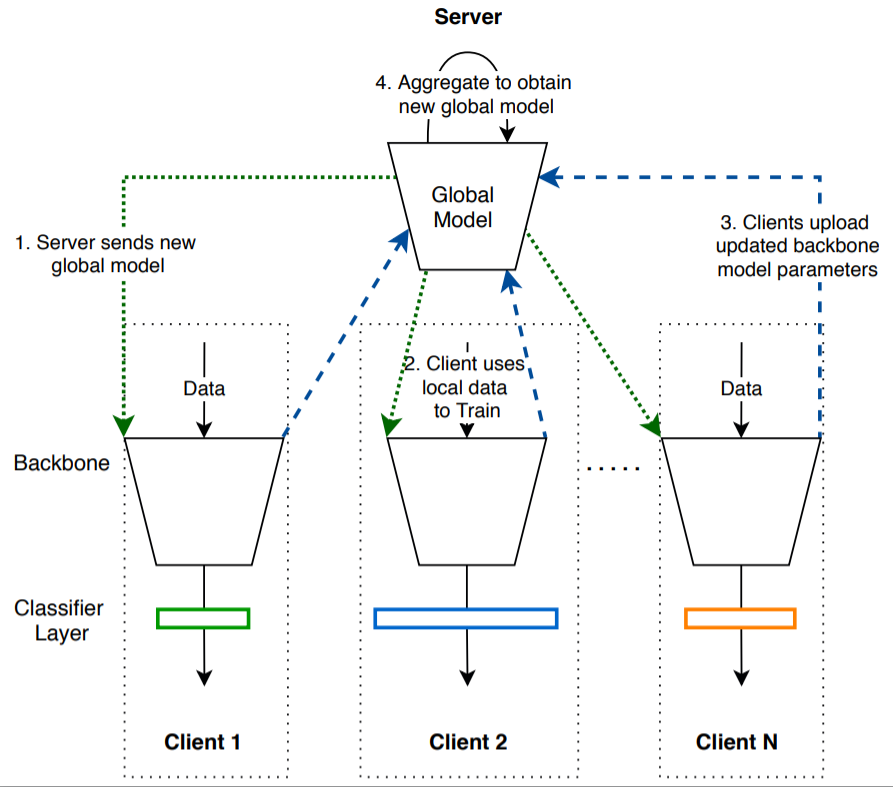
Federated Person Re-identification (FedReID)
Personal re-identification is an important computer vision task, but its development is constrained by the increasing privacy concerns. Federated learning is a privacy-preserving machine learning technique that learns a shared model across decentralized clients. We implement federated learning to person re-identification (FedReID) and optimize its performance affected by statistical heterogeneity in the real-world scenarios.
This is code for ACMMM 2020 oral paper - Performance Optimization for Federated Person Re-identification via Benchmark Analysis
Algorithm: Federated Partial Averaging (FedPav)
Prerequisite
It requires the following Python libraries:
torch
torchvision
easyfl
Please refer to the documentation to install easyfl.
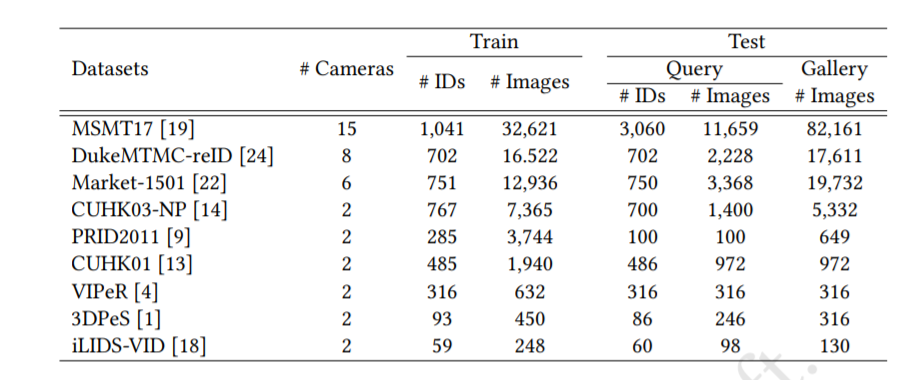
Datasets
We use 9 popular ReID datasets for the benchmark.
🎉 We are now releasing the processed datasets. (April, 2022)
Please email us to request for the datasets with:
- A short self-introduction.
- The purposes of using these datasets.
⚠️ Further distribution of the datasets are prohibited.
Run the experiments
Put the processed datasets in data_dir and run the experiments with the following scripts.
python main.py --data_dir ${data_dir}
You can refer to the main.py to run experiments with more options and configurations.
Note: you can run experiments with multiple GPUs by setting
--gpu. The default implementation supports running with multiple GPUs in a slurm cluster. You may need to modifymain.pyto usemultiprocess.
You may refer to the original implementation for the optimization methods: knowledge distillation and weight adjustment.
Citation
@inproceedings{zhuang2020performance,
title={Performance Optimization of Federated Person Re-identification via Benchmark Analysis},
author={Zhuang, Weiming and Wen, Yonggang and Zhang, Xuesen and Gan, Xin and Yin, Daiying and Zhou, Dongzhan and Zhang, Shuai and Yi, Shuai},
booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
pages={955--963},
year={2020}
}
@article{zhuang2023fedreid,
title={Optimizing performance of federated person re-identification: Benchmarking and analysis},
author={Zhuang, Weiming and Gan, Xin and Wen, Yonggang and Zhang, Shuai},
journal={ACM Transactions on Multimedia Computing, Communications and Applications},
volume={19},
number={1s},
pages={1--18},
year={2023},
publisher={ACM New York, NY}
}