feature_selection.md 8.4 KB
Hetero Feature Selection
Feature selection is a process that selects a subset of features for model construction. Taking advantage of feature selection can improve model performance.
In this version, we provide several filter methods for feature
selection. Note that module works in a cascade manner where
selected result of filter A will be input into next filter B.
User should pay attention to the order of listing when
supplying multiple filters to filter_methods param in job configuration.
Features
Below lists available input models and their corresponding filter methods(as parameters in configuration):
| Isometric Model | Filter Method |
|---|---|
| None | manually percentage_value |
| Binning | iv_filter(threshold) iv_filter(top_k) iv_filter(top_percentile) |
| Statistic | statistic_filter |
| Pearson | correlation_filter(with 'iv' metric & binning model) vif_filter |
| SBT | hetero_sbt_filter hetero_fast_sbt_filter |
| PSI | psi_filter |
Most of the filter methods above share the same set of configurable parameters. Below lists their acceptable parameter values.
| Filter Method | Parameter Name | metrics | filter_type | take_high |
|---|---|---|---|---|
| IV Filter | filter_param | "iv" | "threshold", "top_k", "top_percentile" | True |
| Statistic Filter | statistic_param | "max", "min", "mean", "median", "stddev", "variance", "coefficient_of_variance", "skewness", "kurtosis", "missing_count", "missing_ratio", quantile(e.g."95%") | "threshold", "top_k", "top_percentile" | True/False |
| PSI Filter | psi_param | "psi" | "threshold", "top_k", "top_percentile" | False |
| VIF Filter | vif_param | "vif" | "threshold", "top_k", "top_percentile" | False |
| Hetero/Homo/HeteroFast SBT Filter | sbt_param | "feature_importance" | "threshold", "top_k", "top_percentile" | True |
unique_value: filter the columns if all values in this feature are the same
iv_filter: Use iv as criterion to selection features. Support three mode: threshold value, top-k and top-percentile.
- threshold value: Filter those columns whose iv is smaller than threshold. You can also set different threshold for each party.
- top-k: Sort features from larger iv to smaller and take top k features in the sorted result.
- top-percentile. Sort features from larger to smaller and
take top percentile.
Besides, multi-class iv filter is available if multi-class iv has been calculated in upstream component. There are three mechanisms to select features. Please remind that there exist as many ivs calculated as the number of labels since we use one-vs-rest for multi-class cases.
- "min": take the minimum iv among all results.
- "max": take the maximum ones
* "average": take the average among all results. After that, we get unique one iv for each column so that we can use the three mechanism mentioned above to select features.
statistic_filter: Use statistic values calculate from DataStatistic component. Support coefficient of variance, missing value, percentile value etc. You can pick the columns with higher statistic values or smaller values as you need.
psi_filter: Take PSI component as input isometric model. Then, use its psi value as criterion of selection.
hetero_sbt_filter/homo_sbt_filter/hetero_fast_sbt_filter: Take secureboost component as input isometric model. And use feature importance as criterion of selection.
manually: Indicate features that need to be filtered.
percentage_value: Filter the columns that have a value that exceeds a certain percentage.
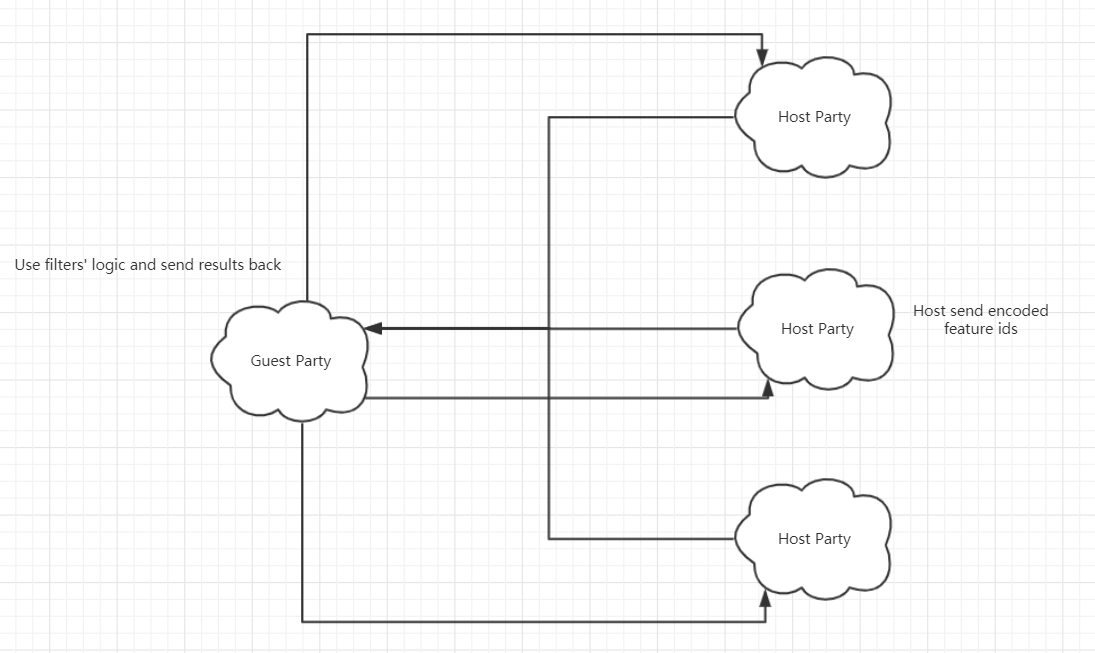
Besides, we support multi-host federated feature selection for iv filters. Hosts encode feature names and send the feature ids that are involved in feature selection. Guest use iv filters' logic to judge whether a feature is left or not. Then guest sends result back to hosts. Hosts decode feature ids back to feature names and obtain selection results.