
feature_binning.md 7.7 KB
Hetero Feature Binning
Feature binning or data binning is a data pre-processing technique. It can be use to reduce the effects of minor observation errors, calculate information values and so on.
Currently, we provide quantile binning and bucket binning methods. To achieve quantile binning approach, we have used a special data structure mentioned in this paper. Feel free to check out the detail algorithm in the paper.
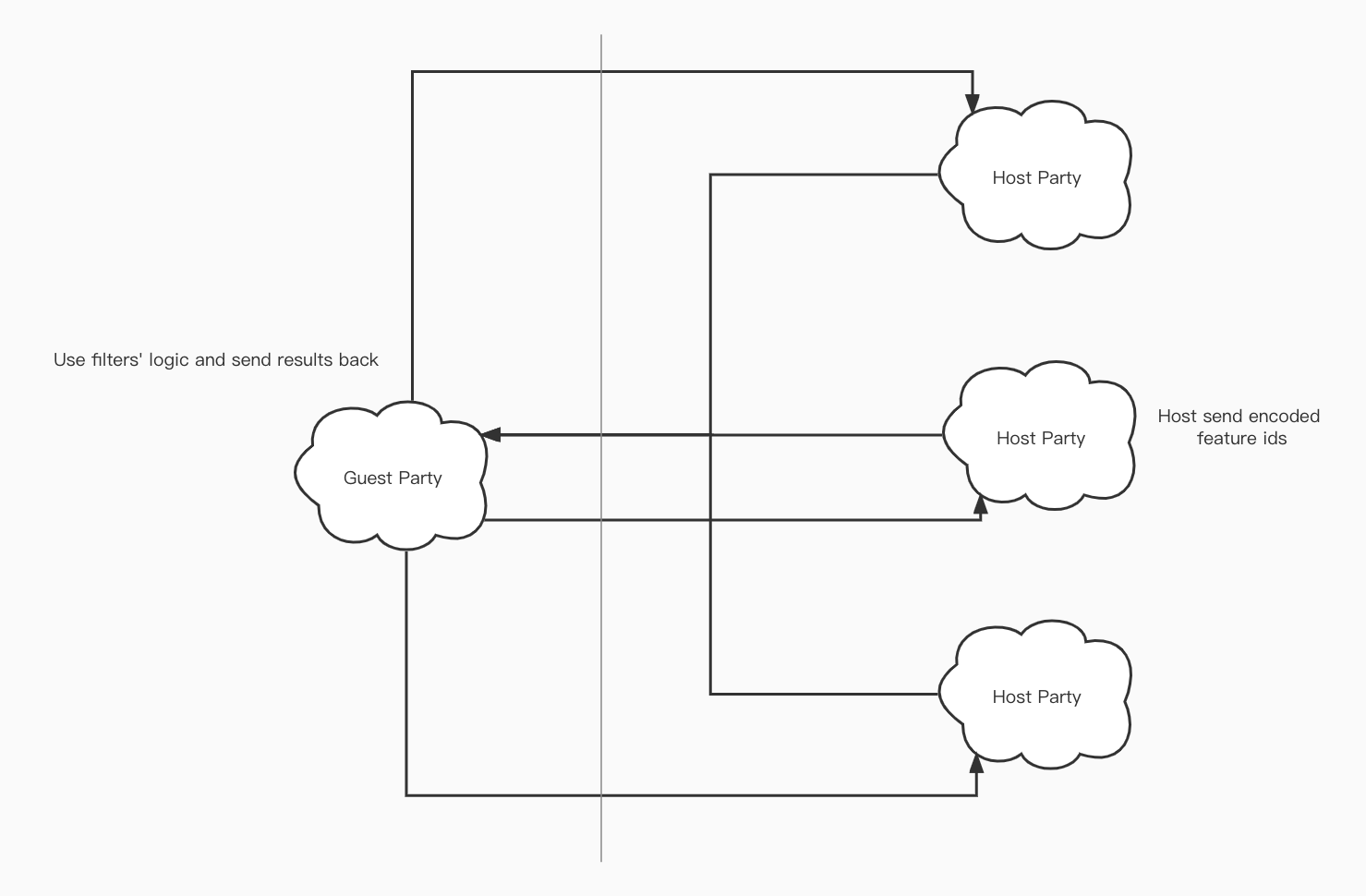
As for calculating the federated iv and woe values, the following figure can describe the principle properly.

As the figure shows, B party which has the data labels encrypt its labels with Addiction homomorphic encryption and then send to A. A static each bin's label sum and send back. Then B can calculate woe and iv base on the given information.
For multiple hosts, it is similar with one host case. Guest sends its encrypted label information to all hosts, and each of the hosts calculates and sends back the static info.
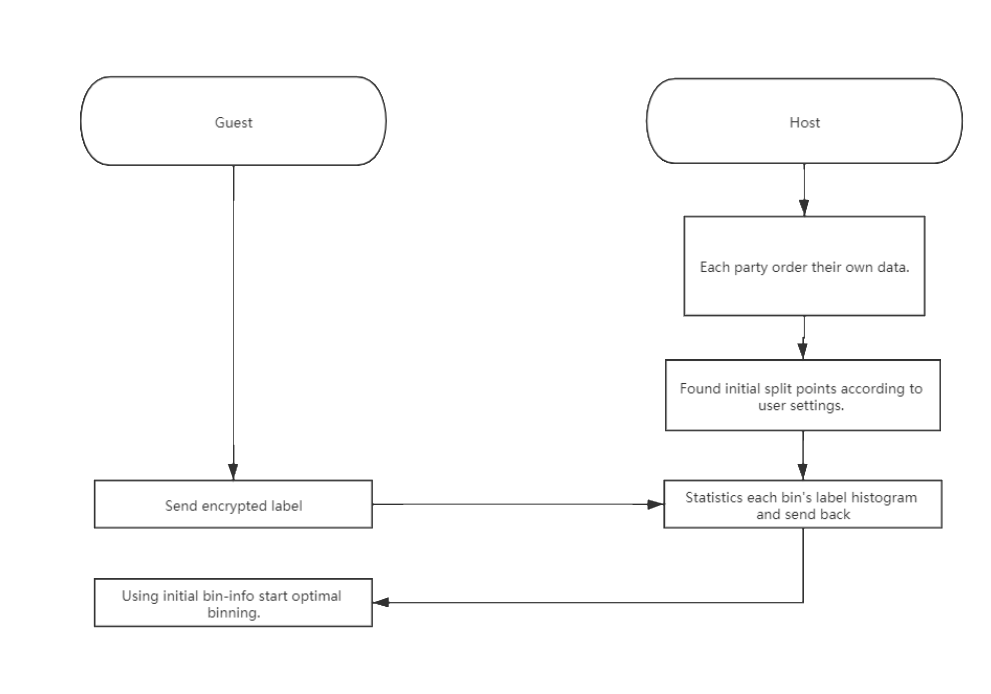
For optimal binning, each party use quantile binning or bucket binning find initial split points. Then Guest will send encrypted labels to Host. Host use them calculate histogram of each bin and send back to Guest. Then start optimal binning methods.
There exist two kinds of methods, merge-optimal binning and split-optimal binning. When choosing metrics as iv, gini or chi-square, merge type optimal binning will be used. On the other hand, if ks chosen, split type optimal binning will be used.
Below lists all metrics of optimal binning:
| Optimal Binning Metric Type | Input Data Case |
|---|---|
| chi-square | dense input sparse input |
| gini | dense input sparse input |
| iv | dense input sparse input |
| ks | dense input sparse input |
Binning module supports multi-class data to calculate iv and woe too. To achieve it, one-vs-rest mechanism is used. Each label will be chosen iteratively as event case. All other cases will be treated as non-event cases. Therefore, we can obtain a set of iv&woe result for each label case.
Features
- Support Quantile Binning based on quantile summary algorithm.
- Support Bucket Binning.
- Support missing value input by ignoring them.
- Support sparse data format generated by dataio component.
- Support calculating woe and iv as well as counting positive and negative cases for each bin.
- Support transforming data into bin indexes or woe value.
- Support multiple-host binning.
- Support 4 types of optimal binning.
- Support asymmetric binning methods on Host & Guest sides.
- Support multi-class iv&woe calculation.
Below lists supported features:
| Cases | Scenario |
|---|---|
| Input Data with Missing Value | bucket binning quantile binning |
| Input Data with Categorical Features | bucket binning quantile binning optimal binning |
| Input Data in Sparse Format | bucket binning quantile binning optimal binning |
| Input Data with Multi-Class(label) | single host multi-host |
| Output Data Transformed | bin index woe value(guest-only) |
| Skip Statistic Calculation | bucket binning quantile binning |