
 Shellmiao
7cd6e4c9e6
Add Pycharm files
Shellmiao
7cd6e4c9e6
Add Pycharm files
|
2 years ago | |
|---|---|---|
| .idea | 2 years ago | |
| FATE-Flow | 2 years ago | |
| Fate | 2 years ago | |
| README.md | 2 years ago |
README.md
Fate-flow源码阅读记录
环境配置
将Fate-flow项目PULL至本地,链接为: https://github.com/FederatedAI/FATE-Flow
Python使用版本:
- Python 3.6
Pip安装需要的包:
- grpcio
- requests
- werkzeug
- flask
- requests_toolbelt
- cachetools
- ruamel
- ruamel.yaml
- filelock
- peewee
pip install grpcio requests werkzeug flask requests_toolbelt cachetools ruamel ruamel.yaml filelock peewee -i https://pypi.mirrors.ustc.edu.cn/simple/
由于需要引用Fate项目中的代码,需要将Fate项目PULL下来做引用
- 将Fate项目从此处PULL下来
- 在项目所使用的Python环境根目录下,寻找\Lib\site-packages目录,在其中创建mypath.pth文件
- 在mypath.pth文件中写入Fate以及Fate flow项目的绝对路径
Fate总体架构

具体各个模块的说明如下:
- FATE Flow: 联邦学习的任务流水线管理模块(通俗理解就是调度器)
- FederatedML: 联邦机器学习的 Python 实现包(类比 scikit-learn)
- Cluster Manager: 集群管理器
- Node Manager: 节点管理器,管理每台机器的计算资源
- RollSite: 跨 Party 通讯组件
- Mysql: 数据库,FATE Flow 和 Cluster Manager 的数据在此存储
Fate Flow架构
Fate Flow架构图
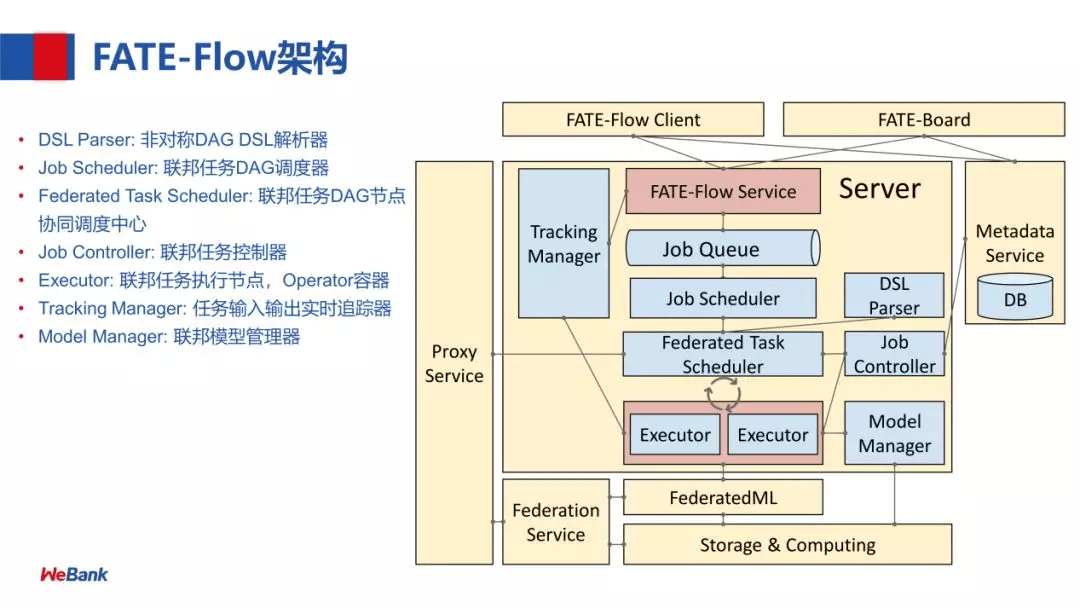
各个模块的功能如下(来自 构建端到端的联邦学习 Pipeline 生产服务):
- DSL Parser:是调度的核心,通过 DSL parser 解析到一个计算任务的上下游关系及依赖等。
- Job Scheduler:是 DAG 层面的调度,把 DAG 作为一个 Job,DAG 里面的节点执行称为 task,也就是说一个 Job 会包含若干个 task
- Federated Task Scheduler:最小调度粒度就是 task,需要调度多方运行同一个组件但参数算法不同的 task,结束后,继续调度下一个组件,这里就会涉及到协同调度
- Job Controller:联邦任务控制器
- Executor:联邦任务执行节点,支持不同的 Operator 容器,现在支持 Python 和 Script 的 Operator。Executor,在我们目前的应用中拉起 FederatedML 定义的一些组件,如 data io 数据输入输出,特征选择等模块,每次调起一个组件去执行,然后,这些组件会调用基础架构的 API,如 Storage 和 Federation Service (API 的抽象) ,再经过 Proxy 就可以和对端的 FATE-Flow 进行协同调度。
- 注:这里还用老版本的说明,即 Proxy+Federation,最新版本统一为 RollSite
- Tracking Manager:任务输入输出的实时追踪,包括每个 task 输出的 data 和 model。
- Model Manager:联邦模型管理器
联邦学习任务多方协同调度
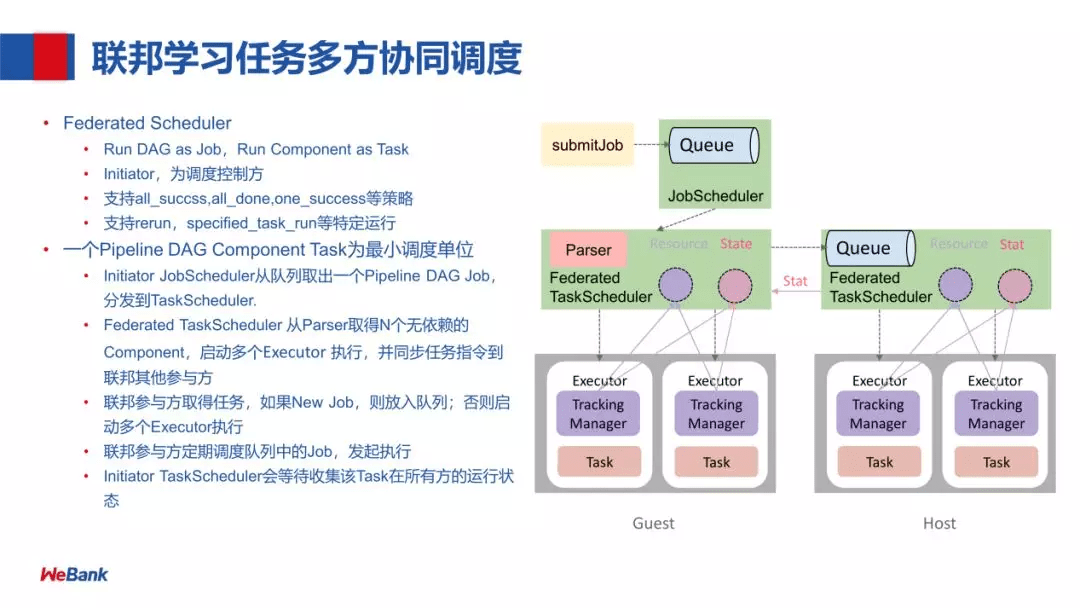
- 首先,是以任务提交的一种方式,提交任务到 Queue
- 然后 JobScheduler 会把这个任务拿出来给到 Federated TaskScheduler 调度,Federated TaskScheduler 通过 Parser 取得下游 N 个无依赖的 Component
- 再调度 Executor (由两部分组成:Tracking Manager 和 Task) 执行,同时这个任务会分发到联邦学习的各个参与方 Host
- 联邦参与方取得任务,如果是 New Job,则放入队列(参与方会定期调度队列中的 Job),否则启动多个 Executor 执行
- Executor 在 run 的过程中,会利用 Federation API 进行联邦学习中的参数交互
- 对一个联邦学习任务,每一方的 Job id 是保持一致的,每跑一个 Component,它的 Task id 也是一致的
- 每个 Task 跑完 Initiator TaskScheduler 会收集各方的状态,进行下一步的调度